
Do not index
Canonical URL
Are you considering NannyML as your ML monitoring solution? But first, you would like to evaluate its algorithms, assess how easy it is to put into production and confirm its compatibility with your use cases? Fair enough!
This guide will help you design a proof-of-concept (PoC) project to validate that NannyML is the right tool to capture and prevent ML model failures for your use cases.
Designing the PoC
The PoC is designed to retroactively monitor one of your current ML models on historical data so you can:
- Evaluate NannyML's accuracy in detecting recent model failures.
- Assess NannyML's root-cause-analysis (RCA), issue resolution capabilities, and overall monitoring workflow.
- Determine the additional value provided by the paid product, NannyML Cloud.
Let's begin by selecting the model to evaluate it.
Step 1: Deciding on a model
We advise you to evaluate NannyML using a model that is already in production. You can pick any model that fits into a classification or regression use case.
If the model has previously experienced performance issues, it is the perfect candidate to evaluate NannyML and check whether performance estimation algorithms would have caught the model failures.
Common models and use cases monitored by our customers using nannyML in production include the following:
- Demand forecasting.
- Loan default prediction.
- Predictive maintenance.
One thing these use cases have in common is that model performance is mission-critical. Use cases like these often involve delayed or absent ground truth. And since NannyML excels at estimating model performance without immediate access to ground truth during production, models like these are excellent options for evaluating NannyML’s features.
So, if the majority of your models in production are mission-critical, use a mission-critical model to evaluate NannyML; this would really show the benefits that performance estimation can give to your monitoring workflow. Otherwise, opt for a model that has a big impact on business decisions. This would allow you to observe how data changes affect your model's predictions and act faster to any eventual degradation.
Summary tips:
- Ideally, use a model already in production.
- Ideally, use a model that has faced performance issues.
- Ideally, use a model where ground truth becomes available after a certain period, this is particularly useful when comparing NannyML's estimated results to actual values.
Step 2: Getting the right data
As per the data, we must build a reference and a monitored dataset. The reference set will serve as a golden dataset to establish a baseline; it will be used to fit NannyML's estimators.
The monitored set is where NannyML monitors the model’s performance and checks for data drift using the knowledge gained from studying the reference set.
Question: How many observations should the reference and monitored sets contain?
- Reference set: We advise using at least one year's worth of data from around six months ago. This will give NannyML's estimators the full context of the model's behaviour over a whole year. If you have created a robust test set and you know your model's performance is good on it, the test set can also be a good candidate to establish your monitoring baselines.
- Monitored set: We advise using at least the last six months of data. Ideally, this data contains ground truth (targets/labels). This is not because performance estimation needs them but because it would ease your NannyML evaluation since you can compare NannyML's estimations against actual values.
Summary tips:
- For the reference set, we need at least one year's worth of data from six months ago. The model's test set is also a good option.
- For the monitored set, we recommend using at least the previous 6 months of data.
- Ideally, the monitored set contains targets to ease the evaluation of NannyML's performance estimation algorithms.
Step 3: Running the analysis
Once you have decided on the model and created the reference and monitored sets, it is time to put NannyML into practice and run the evaluation analysis.
We suggest running a historical monitoring analysis following this ML Monitoring Workflow.
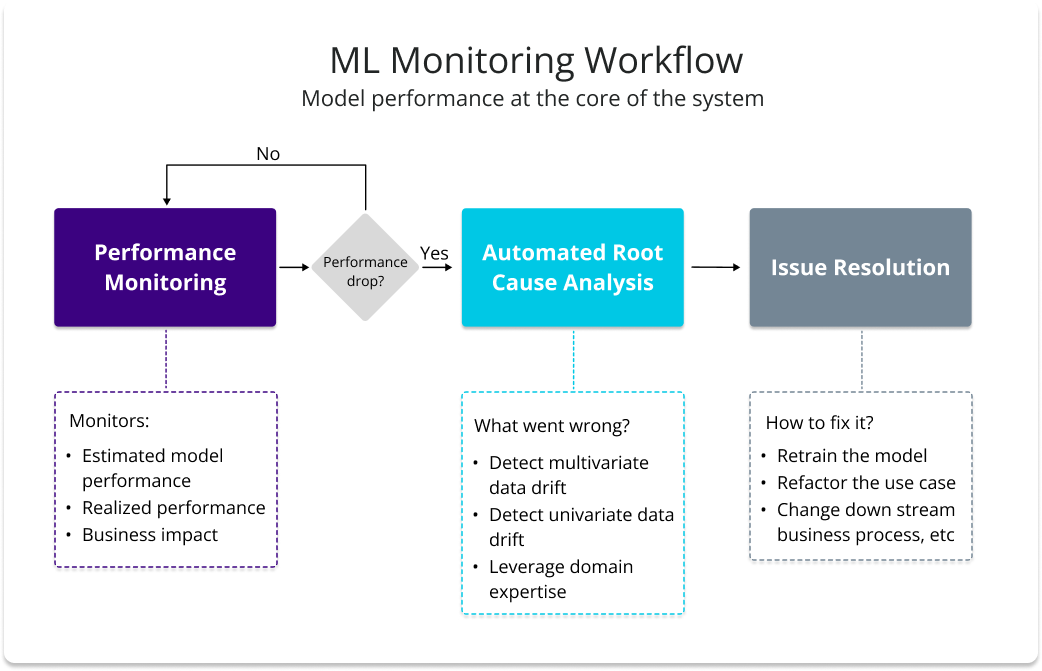
Performance Monitoring
We start by monitoring the model's performance. This means monitoring estimated and realized performance plus business impact.
In practice, this translates to using CBPE (classification) or DLE (regression) to estimate the model's performance and the PerformanceCalculator method to calculate the realized performance over time.
If you are working on a classification use case, you can define a business value matrix and use NannyML to plot the estimated and realized business impact of your model.
This first step will allow you to:
- Observe how the model's performance and business impact has changed over time.
- Check if there has been any real performance degradation.
- Assess in which capacity NannyML captured any performance degradation.
If you are running the PoC on NannyML Cloud or using NannyML's premium algorithms on AWS Sagemaker, you also have access to M-CBPE, another performance algorithm that is 10-30% more accurate than normal CBPE.
Root Cause Analysis
The idea here is to figure out what caused the performance issue. We do it by running a root cause analysis (RCA). To conduct an RCA, apply multivariate and univariate drift detection methods, concept drift methods, summary statistics, and data quality checks. These measures help assess which drifts correlate the most to the changes in the model's performance.
Issue Resolution
The final step involves assessing whether the information gathered from the previous two steps provides a clear path to address any performance issues.
- Have several features drifted significantly? Is this behaviour likely to continue happening? Consider retraining your model.
- Has the problem's concept changed? It may be time to build a new training set that reflects the new concept or potentially reframe the use case.
- Was the issue due to a poor data quality problem? Focus on fixing those data pipelines.
- Did the performance remain unchanged, but the business impact shifted dramatically? Reconsider which metric to prioritise for model evaluation.
Once the underlying issue has been identified, these and other strategies for issue resolution can be applied to tackle performance problems.
Step 4: Quantifying how much value NannyML can bring
After gathering all the results from the historical performance analysis, we recommend teams to translate them into monetary terms. For instance, consider calculating:
- The potential savings by preventing model failures.
- The potential savings by optimising retraining. Instead of adhering to a fixed schedule, retrain only when the estimated performance decreases.
- The time saved on monitoring and maintenance. Compare the time spent on monitoring using your previous solution with the current time spent.
How much time does the PoC should take?
The duration of the POC depends on your team's bandwidth and the complexity of your use case, but here is a suggested timeline:
- Week 1: Select a model and gather the necessary data.
- Week 2: Create the reference and monitored sets.
- Week 2 - 3:
- Perform Performance Monitoring
- Conduct Root Cause Analysis
- Address Issue Resolution
- Week 4: Quantify the value NannyML can bring.
NannyML Cloud vs NannyML OSS
You've evaluated NannyML and weighed its benefits. Now, the key question is: Should you go for NannyML OSS or plugin NannyML Cloud?
The answer depends on your needs and how much engineering you're ready for. To help you decide, let's compare NannyML OSS and NannyML Cloud.
NannyML OSS covers the essentials, offering tools for monitoring ML models. It includes two performance estimation algorithms (CBPE, DLE), drift detection (univariate and multivariate), plus summary stats and data quality checks.
NannyML Cloud has all those features and an extra accurate performance estimation algorithm (M-CBPE), surpassing CBPE by 10-30%. It also detects concept shifts and has automated alerts.
The big difference? NannyML Cloud handles engineering and infrastructure, allowing direct deployment of your cloud while keeping your data secure. It offers out-of-the-box automated alerts and supports multiple model monitoring through programmable data collection and setup by NannyML Cloud SDK.
Similar things can be achieved with the OSS version but require serious engineering. So, if you want to monitor many models, get automatic alerts, and spot concept shifts easily, NannyML Cloud might be simpler. Otherwise, NannyML OSS is still a solid choice. Check out the NannyML Cloud vs OSS feature table for a deeper comparison.
Written by
