Table of Contents
- What are SageMaker Algorithms?
- What’s the difference between OSS NannyML and NannyML SageMaker Algorithms?
- Walkthrough of how to monitor ML models in production with the NannyML SageMaker Algorithm
- 1. Subscribe to a NannyML Algorithm on the AWS Marketplace
- 2. Launch a SageMaker Notebook Instance
- 3. Configure the NannyML Algorithm
- 4. Fit the NannyML Algorithm on reference data
- 5. Perform batch transform on production data
- 6. Check the model performance
- Conclusion
.png?table=block&id=f489570a-c562-4394-9875-cfe3c996595d&cache=v2)
Do not index
Canonical URL
In this blog post, I will walk you through how to deploy the NannyML Monitoring Algorithms, available on the AWS Cloud marketplace, in production.
After reading this post, you will:
- Understand how convenient it is to use NannyML SageMaker Algorithms for monitoring
- Have your mind blown by how much engineering and software integration AWS Sagemaker automatically takes care of.
We will deploy NannyML’s flagship algorithm for the walkthrough: performance estimation. This algorithm can estimate a machine learning model's performance in production without accessing targets. Excellent for use cases where the ground truth is absent or delayed. Like in the case of loan default prediction, where you have to wait until the end of the loan to know whether someone could pay the loan back or not.
But before we delve into that, let’s first look at (1) what SageMaker Algorithms are and (2) how the NannyML Algorithms fit that paradigm.
What are SageMaker Algorithms?
Amazon SageMaker is a fully managed service provided by AWS (Amazon Web Services) that allows developers and data scientists to build, train, and deploy machine learning (ML) models more efficiently. There are three types of SageMaker algorithms:
- Built-in Algorithms: SageMaker offers a collection of predefined algorithms that cater to a wide range of ML tasks, such as classification, regression, clustering, and more. These algorithms are optimized for performance, scalability, and reliability on AWS infrastructure. Think the usual suspects: XGBoost, K-nearest neighbors, etc.
- Custom Algorithms: Apart from the built-in algorithms, SageMaker users can also package their own algorithms and use them within SageMaker. This offers flexibility for data scientists who wish to deploy specialized or proprietary models. For instance, if a researcher develops a new type of neural network architecture, a unique optimization method, or even a locally trained model.
- Marketplace Algorithms: The AWS Marketplace allows software vendors and data science companies to package and sell their ML algorithms. Once users subscribe to these algorithms, they can be used seamlessly within SageMaker. From Hard Hat Detectors for Worker Safety to Contract Clause Extraction models. The monitoring Algorithms of NannyML can also be found here.
When you find an algorithm on the AWS Marketplace that suits your needs, you can subscribe to it with just a few clicks. There's no need to download software, install dependencies, or configure settings manually. Marketplace algorithms are packaged in a manner that is directly compatible with SageMaker. This ensures you can start using the algorithm immediately once you've subscribed. On top of that, they can be utilized in SageMaker just like any built-in algorithm and access datasets stored in Amazon S3 or other AWS data stores without needing separate connectors or data transfer tools. It’s also worth noting that SageMaker's ability to auto-scale resources and optimize workloads extends to Marketplace algorithms. Last but least, there is also some friction removal when it comes to billing: the cost of using Marketplace algorithms is added directly to your AWS bill, eliminating the need for separate financial transactions or agreements.
What’s the difference between OSS NannyML and NannyML SageMaker Algorithms?
NannyML’s open-source monitoring algorithms follow the scikit-learn paradigm:
- They get fit on the test set, and
- Predict metrics on production data.
Funnily enough SageMaker Algorithms are designed similarly, they have the same two logical components: training and inference. This is great because that means that the NannyML SageMaker Algorithms can stay true to the open-source NannyML interface we've all come to love:
- You can create a training job in SageMaker to fit a NannyML Algorithm. Sagemaker will save the generated monitoring artifacts to an Amazon S3 bucket.
- The inference component then uses those artifacts to run batch transform jobs to estimate model performance metrics on production data.
With the added advantage, you don’t have to think about infrastructure, deployment, or hosting because SageMaker takes care of those automatically. Both steps are visualised below, and both only take one command to execute. Magic.
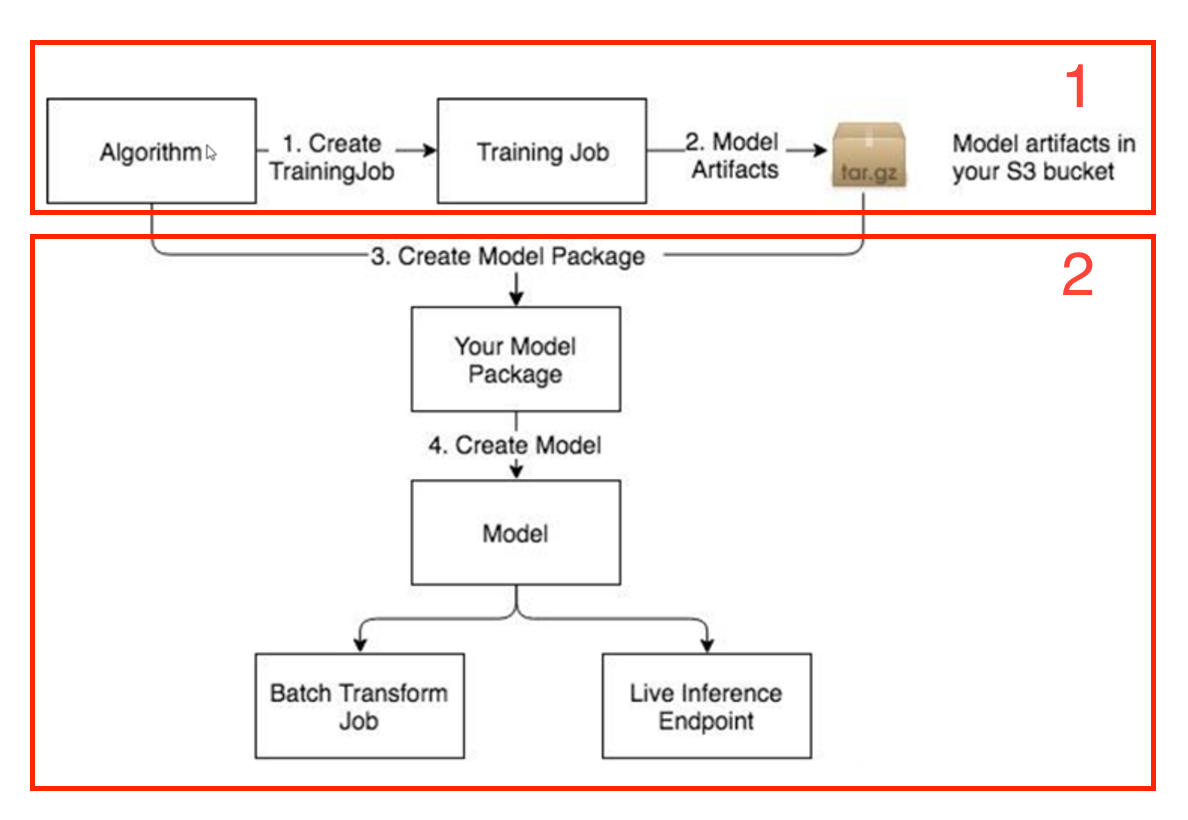
Walkthrough of how to monitor ML models in production with the NannyML SageMaker Algorithm
1. Subscribe to a NannyML Algorithm on the AWS Marketplace
2. Launch a SageMaker Notebook Instance

One of the small notebook instance types like the
ml.t3.large, should do the trick.If you want to run NannyML on your own Notebook Instance, you can use this example Jupyter Notebook. We have also prepared some data (for regression, classification; binary and multiclass) so you can quickly try it out. Both can be found in this repository.
3. Configure the NannyML Algorithm
Start with importing the relevant libraries:
import sagemaker as sage
import pandas as pd
import jsonSagemaker requires you to provide an Amazon Resource Name (ARN). This is used to uniquely identify AWS resources. AWS requires an ARN when you need to specify a resource unambiguously across all of AWS. The NannyML ARN, corresponding to your region, can be retrieved from the subscription page - under configuration.
nml_performance_estimation_arn = "paste the NannyML ARN here"Set the path to the reference dataset. NannyML will use the reference dataset to establish a baseline for model monitoring. Ideally, the reference data comes from a period where the model was behaving as expected, a so-called golden period. An ideal candidate for reference is the test set.
reference_dataset_location = f"s3://{bucket}/{key_prefix}/test_set.csv"It’s best to explicitly set the output location on S3, where SageMaker will store the results from fitting a NannyML Algorithm (model artifacts and output files).
output_location = f"s3://{bucket}/{key_prefix}/performance_estimation/output"
Configure the relevant NannyML Algorithm and SageMaker parameters:
nannyml_parameters = {
"y_pred_proba": "predicted_probability",
"y_pred": "prediction",
"y_true": "target",
"timestamp_column_name": "timestamp",
"problem_type": "classification_binary",
"metrics": ["roc_auc"],
"chunk_period"="Q"
}sagemaker_hyperparameters = {
"data_type": "csv",
"data_filename": reference_dataset_location.split("/")[-1],
"problem_type": "classification_binary",
"parameters": json.dumps(nannyml_parameters),
}Instantiate a SageMaker estimator object with the previously defined parameters, and pick an instance type that SageMaker will spin up for fitting the NannyML Algorithm:
estimator= sage.algorithm.AlgorithmEstimator(
algorithm_arn=nml_performance_estimation_arn,
output_path=output_location,
hyperparameters=sagemaker_hyperparameters,
instance_type='ml.m5.large',
instance_count=1,
sagemaker_session=sage.Session(),
role=sage.get_execution_role(),
)4. Fit the NannyML Algorithm on reference data
Start the training job:
estimator.fit(
{'training': reference_dataset_location}
)5. Perform batch transform on production data
Set the path to the analysis dataset. This dataset contains production data from the period we are interested in monitoring.
analysis_dataset_location = f"s3://{bucket}/{key_prefix}/production_set.csv"Create a transformer object from the fitted NannyML Algorithm. We can take the same output path as before. Again, we have to set an instance type, this time the one that SageMaker will use to carry out the inference. Lastly, execute the batch transform job.
transformer = estimator.transformer(
output_path=output_location
instance_type="ml.m5.large",
instance_count=1,
)
transformer.transform(analysis_dataset_location, content_type="text/csv")
transformer.wait()6. Check the model performance
Have a quick sanity check, and read in the results:
results= pd.read_csv(
output_location + "/" + analysis_dataset_location.split("/")[-1]+ ".out", header=[0,1]
)Conclusion
Harnessing the power of AWS SageMaker and its Marketplace Algorithms can significantly streamline the ML workflow for data scientists. By utilizing NannyML's Monitoring Algorithms from the AWS Marketplace, data scientists are granted a clear pathway to easily deploy and monitor machine learning models in a production. What stands out is the reduction in manual configuration, dependencies, and setup complexities and the preservation of NannyML's beloved open-source interface, which many data scientists have grown fond of.
As we walked through the process, we observed how NannyML has seamlessly integrated its offerings with SageMaker's paradigms. For data scientists, this means less time grappling with infrastructural challenges and more time focusing on what truly matters: deriving insights, optimizing models, and delivering value. As the ML ecosystem evolves, tools and platforms that reduce friction and promote efficiency, like NannyML and AWS SageMaker, will undoubtedly play pivotal roles in shaping the future of data science workflows.
→ Try it out here!
P.S. Stay tuned for new algorithms, like concept drift detection and performance estimation V2, to make their grand entry on the AWS Marketplace soon!
Written by
