Table of Contents
- Part 1: Building the model
- Preparing the dataset
- Preprocessing the data
- Fine-tuning the model
- Evaluating the model on a test set
- Putting the model on production
- Part 2: Estimating model performance on unlabelled data
- Preparing the data for CBPE
- Estimating model performance on unseen production data
- Comparing estimated performance vs realized performance
- How Confidence-based Performance Estimation (CBPE) works
- Conclusion
- Demo and Notebook
- References

Do not index
The performance of machine learning models can deteriorate over time, and NLP models are not the exception. This can happen because of several reasons, one being that the serving data has changed so much that it no longer resembles the data the model was trained on, this is known as data drift.
A particular example of this type of drift in NLP is how the meaning of the word “cell” has changed over time. For a long time the primary meaning of “cell” was “prision cell” but recently it has changed to “cell phone”. In the literature this is known as a cultural shift [1]. Cultural shifts cause semantic changes and with that temporal degradations on language machine learning models.
Another example where language drifts are problematic is in Name Entity Recognition (NER) tasks of social media data.
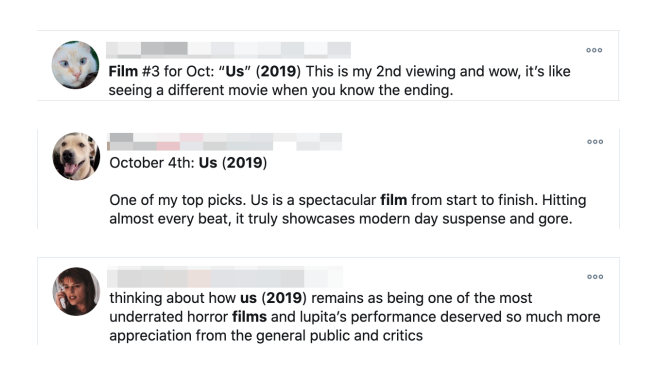
For example, in 2019 the topic “US” became trending on twitter, this sparkled multiple discussions of people thinking that something happened in the United States (U.S.), where in reality the reason the topic was trending was the release of a the movie “US”. But twitter’s topics model assigned both terms “US” and “U.S.” to the same entity, provoking confusion among readers.
In this case the entity “US” (movie) temporarily transformed the meaning of the perviously observed term “US” (country). Causing the model to fail.
These and other similar model failures are hard to catch in realtime, because we can’t measure the performance of the model with the production data since ground truth is absent and labelling new data is often expensive or not an option.
Gladly, there is something we can do uncover these failures. Instead of trying to calculate the exact model performance we can estimate it by leveraging the uncertainty of the model’s predictions and mapping it to performance. To do it we can use nannyML, an open-source library that invented two performance estimation algorithms CBPE and DLE.
In this blogpost, I’ll walk you through how to do performance estimation on a text classification model in production.
The post is divided into two parts:
- In the first part we will train and deploy a text classification model using hugging face, on the Amazon reviews dataset.
- In the second part we will look how this model is performing in production by using nannyML’s performance estimation algorithm.
After reading this you won’t ever have the problem of having now clue how your models are performing when ground truth is absent.
Part 1: Building the model
We want to build a model that predicts the sentiment (Negative, Neutral, Positive) of a review left on Amazon. To do this, we’ll prepare a training dataset with reviews labeled with the appropriate sentiment, assuming that these examples were initially tagged by humans.
The challenge arises when we put the model into production, and new, unlabeled reviews come in. Since humans are no longer part of the equation, and real labels won’t be present, monitoring the model’s performance will be impossible, won’t it? 🧐
Preparing the dataset
We will use the Multilingual Amazon Reviews Dataset to build the sentiment analysis model. This dataset contains thousands of Amazon product reviews in many languages and is typically used to benchmark multilingual classifiers. However, to simplify things a bit, we will only use a subset of the English reviews.
Let’s download the English partition from the Hugging Face Hub.
from datasets import load_dataset
amazon_reviews_raw = load_dataset("amazon_reviews_multi", "en")
amazon_reviews_rawDatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})As you can see, the data is already split, with 200,000 samples for training and 5,000 in the validation and test sets.
Since the ultimate goal of this tutorial is to evaluate the model on unseen post-deployment data and estimate its performance, we will adjust these partitions and create an additional one called production.
Lets consider half of the test set as production data - because it is also unseen data.
test_production_ds = amazon_reviews_raw['test'].train_test_split(test_size=0.5)
test_ds = test_production_ds['train']
production_ds = test_production_ds['test']Then to make the example run faster, lets reduce the size of the of training and validation datasets.
train_ds = amazon_reviews_raw['train'].select(range(6000))
validation_ds = amazon_reviews_raw['train'].select(range(1400))Now, lets put everything back together in a single DatasetDict called
small_amazon_reviews for easier manipulation.from datasets import DatasetDict
small_amazon_reviews = DatasetDict({
'train': train_ds,
'validation': validaton_ds,
'test': test_ds,
'production': production_ds)
})
small_amazon_reviewsDatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 6000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 1400
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 2500
})
production: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 2500
})
})
As you can from the cell above now we have four partitions, and we have reduced the training set to 6,000 reviews to make the example faster to run.
Let's take a look at some of the training reviews to make sure everything seems fine.
def show_samples(dataset, num_samples=3, seed=42):
sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
for example in sample:
print(f"\\n'>> Title: {example['review_title']}'")
print(f"'>> Review: {example['review_body']}'")
print(f"'>> Stars: {example['stars']}'")
show_samples(small_amazon_reviews)
'>> Title: Love it!'
'>> Review: Love it! Perfect in my breakfast book over the dining table. Assembly took a little longer then usual, but for $52 I can't complain!'
'>> Stars: 5'
'>> Title: Returned this item due to missing hardware.'
'>> Review: Battery compartment was missing the screw and would not completely shut causing it to pop open. I returned this item and ordered something else instead.'
'>> Stars: 2'
'>> Title: Great stuff!'
'>> Review: Not too salty - very tasty.'
'>> Stars: 5'Preprocessing the data
As you can see from the above snippet, each review has a 'Stars' attribute, which can range from as low as 1 to as high as 5. We will use these star ratings as a proxy to determine whether the review text expresses a negative, neutral, or positive sentiment.
In the real world, this data would have been labeled by a human, but at the moment, we're taking a shortcut to build the use case.
Additionally, as Shrestha, et.al have pointed out in their paper Deep Learning Sentiment Analysis of amazon.com Reviews and Ratings we have to keep in mind that there might be rare examples where an user wrote a positive review but gave 1 or 2 starts or wrote a negative review but gave 4 or 5 stars. [3]
Knowing this, let’s create a new 'Label' attribute based on 'Stars', with the best arbitrary criteria that we can design with the available information: Reviews with 1-2 stars are flagged as Negative, 4-5 stars are Positive, and 3 are Neutral.
# rename review_body to text
small_amazon_reviews = small_amazon_reviews.rename_column("review_body", "text")
# map each star rating to a sentiment
def re_label(example):
label_mapping = {
1: 'negative',
2: 'negative',
3: 'neutral',
4: 'positive',
5: 'positive'
}
example['real_sentiment'] = label_mapping.get(example['stars'])
return example
small_amazon_reviews = small_amazon_reviews.map(re_label)
Next, we need to tokenize and encode our reviews. As per the tokenizer it is advised to use the same tokenizer associated with the pretrained model checkpoint that we’ll use during fine-tuning.
In our case, we will use
nlptown/bert-base-multilingual-uncased-sentiment as our model checkpoint. This model is a bert-base-multilingual-uncased model, fine-tuned for sentiment analysis on the trained partition of the Amazon product reviews.So, why do we need to fine-tune the model if it has already been fine-tuned on the same dataset?
Well, the original model was fine-tuned to predict the star rating (with 5 possible categories) from a product review. However, we are interested in predicting sentiment (with 3 possible categories). So, since we changed the target vector length, we need to run a couple of training steps in order to use it for predictions and inference.
Let’s use the AutoTokenizer class to instantiate our tokenizer from the pretained model checkpoint.
from transformers import AutoTokenizer
model_checkpoint = "nlptown/bert-base-multilingual-uncased-sentiment"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)
Once we have the tokenizer ready we can apply it on our data
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# original sets
train_dataset = small_amazon_reviews["train"]
val_dataset = small_amazon_reviews["validation"]
test_dataset = small_amazon_reviews["test"]
# tokenized sets
tokenized_train = train_dataset.map(preprocess_function, batched=True)
tokenized_val = val_dataset.map(preprocess_function, batched=True)
tokenized_test = test_dataset.map(preprocess_function, batched=True)
Fine-tuning the model
We start by downloading the model checkpoint, to do it we will use the AutoModelForSequenceClassification class, this will download the model’s configuration and cache the weights.
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint,
ignore_mismatched_sizes=True,
num_labels=3)Next, if we want our model to be hosted on the Hub we’ll need to login or create a Hugging Face account and generate a hugging face token, so our notebook is granted written access to the model repository.
from huggingface_hub import notebook_login
notebook_login()Before setting up the fine-tuning procedure let’s define the metrics that we want to track during training. In our case we’ll track accuracy and F1-score.
In the next step we will pass this
compute_metrics function as an argument of the Hugging Face Trainer API, so it knows what metrics to compute during evaluation.import numpy as np
from datasets import load_metric
def compute_metrics(eval_pred):
load_accuracy = load_metric("accuracy")
load_f1 = load_metric("f1")
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
accuracy = load_accuracy.compute(predictions=predictions,
references=labels)["accuracy"]
f1 = load_f1.compute(predictions=predictions,
references=labels, average='macro')["f1"]
return {"accuracy": accuracy, "f1": f1}
We are to the point where we need to define the training hyperparameters and instantiate the Trainer class.
from transformers import TrainingArguments, Trainer
repo_name = "amazon-reviews-sentiment-bert-base-uncased-6000-samples"
training_args = TrainingArguments(
output_dir=repo_name,
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=2,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model='f1',
push_to_hub=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_val,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
Feel free to play around with different hyperparameter settings. What happens when you increase or decrease the learning rate? Are 2 epochs enough to get a good result?
We are all set! We just need to call the trainer object and we would have a fine-tuned model on the Amazon reviews data set that classifies the review into three different classes.
trainer.train()Evaluating the model on a test set
Let’s test the model on the test dataset to see how well it performs.
from sklearn.metrics import f1_score
predictions = trainer.predict(tokenized_test)
preds = np.argmax(predictions.predictions, axis=-1)
print(f"F1-score: {f1_score(y_true=predictions.label_ids,
y_pred=preds,
average='macro')}")
F1-score: 0.7039We got a F1-score of 0.7, quite decent for a model that only took a couple of minutes to train.
Putting the model on production
Let’s simulate our model is in production by pushing it to the Hub and having it predict the sentiment on new data to check if we can estimate its performance.
trainer.push_to_hub()Check out the model at: https://huggingface.co/NannyML/amazon-reviews-sentiment-bert-base-uncased-6000-samples
Part 2: Estimating model performance on unlabelled data
In the previous section, we measured the model’s performance on the test set. However, how can we be sure it will remain performant after deployment? Assuming the training data was labeled by a human, it becomes very expensive to label new production data each time we want to assess if the model has experienced any degradation.
In this section, we’ll use (unlabed) production data to estimate the model’s F1-score without using any targets. We’ll use CBPE for this.
Preparing the data for CBPE
Let’s start by loading our model using the pipeline function.
from transformers import pipeline
model_checkpoint = "NannyML/amazon-reviews-sentiment-bert-base-uncased-6000-samples"
tokenizer_kwargs = {'padding':True, 'truncation':True, 'max_length':512}
sentiment_classification_model = pipeline(model=model_checkpoint,
tokenizer=tokenizer,
**tokenizer_kwargs)
Next, we use the test and production partitions that we created on the first section, to create pandas dataframe versions of them.
test_dataset.set_format("pandas")
prod_dataset.set_format("pandas")
test_df = test_dataset[:]
production_df = prod_dataset[:]
Now, we will pass these dataframes through the model’s pipeline and collect its predictions and predicted probability scores for the test and production sets.
test_predictions = sentiment_classification_model(test_df.text.tolist(),
return_all_scores=True)
prod_predictions = sentiment_classification_model(production_df.text.tolist(),
return_all_scores=True)
The last step is to convert this predictions into a pandas dataframe since that is the type of input that we need to fit CBPE with. For this we have a function that creates a dataframe from the model’s outputs.
import pandas as pd
def create_scores_dataframe(model_outputs):
# Extract scores
scores_list = [[item['score'] for item in row] for row in model_outputs]
# Create dataframe
df = pd.DataFrame(scores_list, columns=['negative_sentiment_pred_proba',
'neutral_sentiment_pred_proba',
'positive_sentiment_pred_proba'])
df['predicted_sentiment'] = np.argmax([df], axis=-1).tolist()[0]
return df
test_predictions_df = create_scores_dataframe(test_predictions)
prod_predictions_df = create_scores_dataframe(prod_predictions)
test_predictions_df.head()
The only missing thing here is that for CBPE to learn how to build an estimated confusion matrix and calibrate probabilities properly we need to add the target label to the
test_predictions_df.reference_df = pd.concat([test_df[['label']], test_predictions_df], axis=1)
reference_df.head()
We don’t need to do this step for the production data since we are assuming that we don’t actually have the targets of the production data.
Estimating model performance on unseen production data
Now that we have a reference dataframe (test model outputs with test targets), we only need to create an instance of CBPE, fit it with the
reference_df, and estimate the performance on the prod_predictions_df.Let’s start by creating an instance of CBPE. Here we need to map a couple of arguments to how they are called on the
reference_df and prod_predictions_df dataframes.import nannyml as nml
cbpe_estimator = nml.CBPE(
y_pred_proba={
'negative': 'negative_sentiment_pred_proba',
'neutral': 'neutral_sentiment_pred_proba',
'positive': 'positive_sentiment_pred_proba'},
y_pred='predicted_sentiment',
y_true='real_sentiment',
problem_type='classification_multiclass',
metrics='f1', # others roc_auc, accuracy, recall, precision, etc
chunk_size=400, # sample size used for each estimated computation
)
Then we fit the
cbpe_estimator on the reference_dfcbpe_estimator.fit(reference_df)
And use it to estimate the F1-score from the
prod_predictions_df dataframeestimated_results = cbpe_estimator.estimate(prod_predictions_df)
estimated_results.plot()
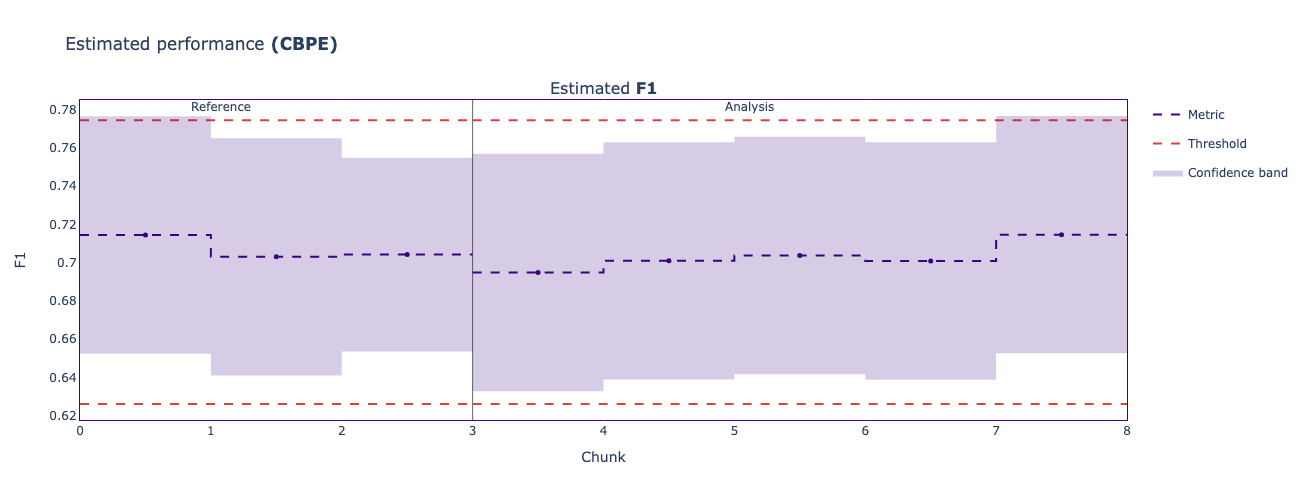
As you can see, the estimated F1-score stays pretty stable across all the reference and analysis periods. Putting a model into production and not knowing at all how good its predictions are can be very stressful, so having visibility that the expected performance is behaving as it did on the test set is really nice to know! And we did it without needing to label any of the production data!
But, can we trust these estimations? How close are these estimations to the real values for the analysis period?
Comparing estimated performance vs realized performance
Since this is an example, and the production data was taken from a partition of the Amazon reviews dataset, we do know the true labels of the analysis period. So we can use this information to asses how good CBPE’s estimations were.
To do this, we first need to add the actual labels to the
prod_predictions_dfprod_predictions_with_target_df = pd.concat([production_df[['label']],
prod_predictions_df], axis=1)
Then, create an instance of the NannyML’s PerformanceCalculator class. Which simply calculates per chunk (sample of data) the performance of an ML model.
calculator = nml.PerformanceCalculator(
y_pred_proba={
'negative': 'negative_sentiment_pred_proba',
'neutral': 'neutral_sentiment_pred_proba',
'positive': 'positive_sentiment_pred_proba'},
y_pred='predicted_sentiment',
y_true='real_sentiment',
problem_type='classification_multiclass',
metrics=['f1'],
chunk_size=400,
)Then, we fit this calculator on
reference_df and make it calculate the performance from the prod_predictions_with_target_df dataframe.calculator.fit(reference_df)
realize_results = calculator.calculate(prod_predictions_with_target_df)Finally, we can compare the these
realized_results to the estimated_results gathered from the CBPE estimation process.results.compare(realize_results).plot()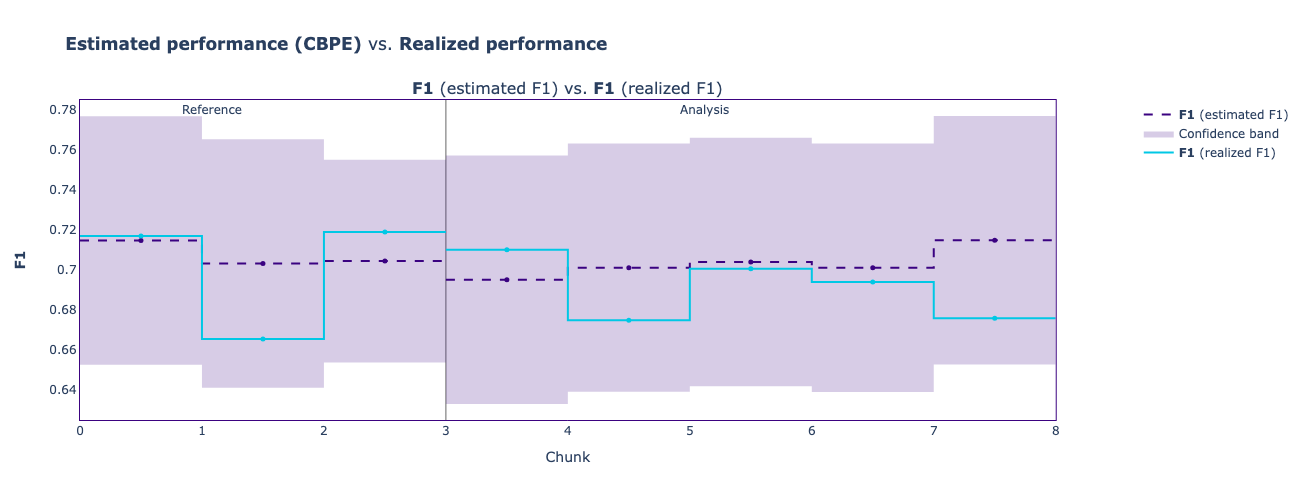
This plot shows how close CBPE’s estimations (purple) were to the actual performance (blue). These estimations can become even more accurate with a larger reference dataset.
How Confidence-based Performance Estimation (CBPE) works
CBPE is an open-source algorithm to estimate performance metrics of binary and multiclass classification models.
It uses the model’s historical outputs (predictions and probability scores) to be able to estimate post-deployment model performance.
You know how classification models usually return predictions along with an associated uncertainty?
Well, this uncertainty score provides information about the confidence of the prediction. A rule of thumb is that the closer the score is to its lower or upper limit (usually 0 and 1), the higher the probability that the classifier’s prediction is correct. When this score is an actual probability, it can be directly used to estimate the probability of making an error. For instance, imagine a high-performing model which, for a large set of observations, returns a prediction of 1 (positive class) with a probability of 0.9. It means that the model is correct for approximately 90% of these observations, while for the other 10%, the model is wrong.
CBPE uses these confidence scores from previous model predictions, usually predictions from the test set, to learn how to build an expected confusion matrix that can later be used to estimate any classification metric without needing a target label. This makes CBPE quite useful for gaining an idea of how an ML model in production is performing without having access to the true predicted classes.
CBPE and other performance estimation algorithms are game-changers, as they help us to:
- Identify temporal degradations in our models.
- Get a view on the performance and business impact of our models, even in cases where ground truth is delayed or absent.
- Prevent losses by catching model failures before they happen, allowing us to prevent actions based on inaccurate predictions.
- Focus on and communicate a single metric effectively.
- Eliminate false covariate shift alerts by quantifying the impact of covariate shift on performance.
- Reduce retraining costs since we know when to retrain, whenever the estimate performance degrades.
If you want to learn more about CBPE, check out these resources to learn more about the math and code behind it.
And if you want to estimate the performance of a regression model, check out the DLE algorithm, which builds an internal ML model under the hood to estimate the loss of the original model.
Conclusion
We built a text-classification model, put it into production, used it to predict the sentiment of new, unseen, and unlabelled Amazon reviews, and successfully estimated the performance of the model on this unlabelled data.
To me, being able to do all that without needing to label any new examples feels like a superpower. If you are curious about how all of this works under the hood, or if you would like to contribute to the project, please check out github.com/nannyml.
Demo and Notebook
We have put together a Hugging Face Space where you can play around with this model and estimate it’s performance on several samples on unseen data. Check it out and have fun!
Check out this Google Colab to play around with this notebook.
References
[1] Cultural Shift or Linguistic Drift? Comparing Two Computational Measures of Semantic Change. https://aclanthology.org/D16-1229.pdf
[2] Mitigating Temporal-Drift: A Simple Approach to Keep NER Models Crisp. https://aclanthology.org/2021.socialnlp-1.14.pdf
[3] Deep Learning Sentiment Analysis of amazon.com Reviews and Ratings. https://arxiv.org/pdf/1904.04096.pdf
[4] How Performance Estimation Works. https://nannyml.readthedocs.io/en/stable/how_it_works/performance_estimation.html#confidence-based-performance-estimation-cbpe
Written by
