
Maslow’s Hierarchy of Needs
As data scientists we often look for ideas in other disciplines to solve our problems. Today, we are looking at an interesting concept we borrowed from psychology: Maslow’s Hierarchy of Needs (1943). What it boils down to is the following:
“Reaching your full potential is only possible
if you have your basic needs covered first.”

The traditional Data Science Hierarchy of Needs
A few years ago, Monica Rogati published a blogpost on hackernoon (2017) making a nice analogy between Maslow’s Hierarchy of Needs and data science. Before you can do any AI or deep learning, you’d better take care of data literacy, data collection, and infrastructure first. This gave birth to the Data Science Hierarchy of Needs:
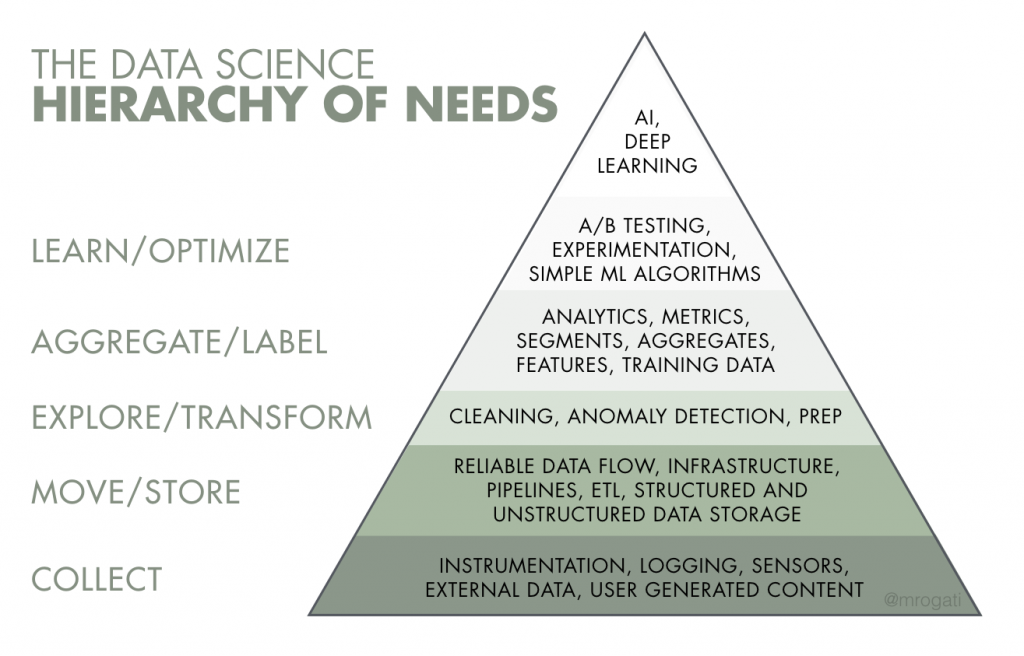
As we all know, AI algorithms require examples to learn from. We would not be able to do much AI training without data gathered from the past. That brings us to the lowest level of the hierarchy which is data acquisition. Be it customer data, open or external data, data generated from sensors or IoT devices, consistently collecting data is a necessity. On top, a rich variety of dense data sources to play around with is literally every data scientist’s dream. However, as we obsess over running reliable, reproducible, and scalable experiments fast, having frictionless data accessibility does not seem like a bad idea.
That is where our second layer comes into play: proper data engineering. Data engineering is all about processing, storing, and exposing real-time and historic data in an efficient way. It is a daunting task to set up scalable data pipelines and to build robust and performant big data infrastructures. Even more so if you want that fully automated through code (DevOps). These are the things our much sought-after data engineering colleagues take care of. Well-orchestrated data flows and friendly data interfaces simplify our subsequent data science tasks by orders of magnitude.
The later stages of the hierarchy form the backbone for successfully training AI models. They can be grouped under data science. We start with EDA (exploratory data analysis): to assess the relevance of the accessible data sources, to define the target, to figure out how various features relate to each other, and to establish a baseline model. This will help us verify the feasibility for our solution approach whilst failing fast. Preferably, only after we have gathered this feedback, should we focus on more advanced data preparation and modelling. That encompasses extensive data wrangling, clever data partitioning, complex feature engineering, elaborate experiment designs, and elegant construction of model architecture. All this, so that we can say we are doing AI and deep learning, right?
The missing pieces
A strong data foundation is vital for the AI maturement process. However, there are some things missing in the current framework.
First of all, let’s take a step back and look at the hierarchy with the end goal in mind. Are we really reaching our full potential as a company if we are just doing AI and deep learning? Is that really the end-all-be-all? Technology itself is never the solution: it’s simply a means to an end, not an end in itself. So, we have to ask ourselves: what are we really trying to achieve using AI? We aim to automate business processes and make informed critical business decisions faster. Doing so, we want our AI systems to be impactful and deliver business value. That is something which is not reflected in top levels of the current framework.
Secondly, Maslow initially described in his Hierarchy of Needs that you can only move up through the various consecutive stages after the previous ones are completely satisfied. In data science, that is not the case. We can perfectly reap value from small AI experiments without having the best data architecture or infrastructure in place. Some companies want to start their data journey with a POC focusing on the upper levels. From a business perspective this makes complete sense. As most tangent business value resides at the top of the Hierarchy. Moreover, having a more profound understanding of the upper-level workings will trickle down knowledge to the rest of the organisation on how to better engineer the lower data levels. It is perfectly fine to use Maslow as an inspiration, but we don’t have to copy this hierarchy principle. Besides, most people already visualise the Hierarchy of Needs as a pyramid rather than a hierarchy. On top, when we progress to build an MVP, we slice this pyramid vertically. Meaning we only build out the minimal required functionality for each layer, which allows us to iterate and gather feedback faster.
Finally, the pyramid needs good ground to stand on. It is evident that when we start a new data science project, we commence by understanding the problem we are trying to solve and grasping the business context surrounding it. We try to ask the right questions, define the business goals, and determine the relevant success criteria. Then we chart out the course of action and only after that, do we start developing stuff. We should apply the same principle on an organisational level when we start building our pyramid. What is missing in the current framework is a comprehensive AI and data strategy.
Towards a more complete AI Pyramid of Needs
We have an expression in our company regarding sales and funding: “the money is only real when it hits the accounts”. The same applies for AI, being real only when it is deployed. It is about creating business value through deployment and making sure AI keeps on delivering business value through observability. And in doing so, making AI trustworthy and reliable. We should update our pyramid to include those two levels and shift our focus on generating business value with AI, instead of just doing AI.

In our new AI Pyramid of Needs, AI observability resides at the top, fulfilling the role of watchful protector. Jeff Bezos would probably agree on treating every day of being deployed as “day one” since according to him: “Day two is stasis. Followed by irrelevance. Followed by excruciating, painful decline. Followed by death.” Quite accurately describing AI algorithms going haywire due to the lack of oversight. Let’s not forget that AI models are fragile pieces of software. It is not uncommon to see them lose 20% of their value in the first 6 months of deployment. While, if not monitored correctly, failing completely silent. A good observability stack detects and alerts data drift, manages machine learning health, and tracks business impact. Keeping these in check will help you prevent, expose, and properly handle algorithmic flaws in production.
However, it is not just about surveillance of performance. Understanding how, why, and when data, business decisions, and AI models are changing makes it possible to fundamentally grasp what is happening on the ground. This way we close an important loop in the data science lifecycle: the one of business understanding. In other words, sophisticated AI monitoring allows us to extract business insights.
Deploying AI models has become significantly more standardized in recent years with the rise of MLOps. Which applies best practices from DevOps and Software Engineering to a machine learning context in an effort to increase efficiency. However, AI deployment is very deserving of its place in the pyramid. As there is literally no business value creation without operationalizing machine learning models in production. Moreover, scalable model serving, model lifecycle management, A/B testing AI solutions, CI/CD, and continuous training (CT) are not trivial.
To prevent machine learning models from failing silently, we've built an open-source monitoring tool. Check our GitHub and support us ⭐ if you find it useful.
Conclusion
A strong data foundation and a solid AI & data strategy are absolutely necessary to leverage business value with AI at scale. However, do they need to be fully fletched out from the start? Absolutely not. We can start small and build our pyramid as we go, or slice it vertically and take it from there. At the end of the day, what is more important is that during our data journey we focus on the right end goal, which is leveraging AI to generate business value. And to make that happen, we need to deploy our AI and have it properly monitored. Our new AI Pyramid of Needs reflects these ideas, and allows us to concentrate on executing the best business strategy to cope with our ever changing data flows.
Sources
McLeod, S. A. (2020, March 20). Maslow’s hierarchy of needs. Retrieved from Simply Psychology: https://www.simplypsychology.org/maslow.html
Rogati, M. (2017, June 12). The Data Science Hierarchy of Needs. Retrieved from HACKERNOON: https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007








.avif)