
Do not index
Canonical URL
Introduction
Data drift is the most frustrating part of our job as data scientists. It is a big challenge in maintaining the performance of our machine-learning models. When the statistical properties of the input data change over time, the model becomes unreliable and can possibly go obsolete. Univariate drift detection focuses on detecting changes in the distribution of an individual feature. It involves comparing newer data distributions to older ones to spot deviations or shifts.
This comprehensive guide will help you understand and tackle data drift by focusing on univariate drift detection methods.
These methods include Jensen-Shannon Distance, Hellinger Distance, Kolmogorov-Smirnov Test, Wasserstein Distance, Chi-squared Test and L-Infinity Distance. To choose from the options, first consider the nature of your data and the specific goal of your analysis.
We will discuss the nuances of these methods and implement them in Python using the NannyML library.
Setting up Environment
The dataset used in this tutorial is the Superstore Sales Dataset from Kaggle. It contains information about the various orders placed at a superstore, such as Order Date, Ship Date, Shipping Mode, Sales, and more. Datasets like these may exhibit univariate drift due to changes in customer behaviour, shifts in market trends, or alterations in business operations.
First, we load the dataset in a Pandas DataFrame and preprocess it using the appropriate steps. Lastly, we split the DataFrame into a reference set and a monitored dataset. The monitored data is also known as analysis set. Check out this detailed guide on why we need to split our data in this manner.
import numpy as np
import pandas as pd
data =pd.read_csv("train.csv")
df = pd.DataFrame(data=data)df['Order Date'] = pd.to_datetime(df['Order Date'], format='%d/%m/%Y')
df['Ship Date'] = pd.to_datetime(df['Ship Date'], format='%d/%m/%Y')
df['Sales'] = df['Sales'].astype(float)
df['Postal Code'] = df['Postal Code'].astype(str)
categorical_columns = [
'Ship Mode', 'Customer ID', 'Customer Name','Segment', 'Country',
'City', 'State', 'Region', 'Product ID', 'Category','Sub-Category',
'Product Name'
]
for col in categorical_columns:
df[col] = df[col].astype('category')
rows_with_zeros = df[df.eq(0).any(axis=1)]
df = df.drop(rows_with_zeros.index)
df.sort_values(by='Order Date', inplace=True)
mid_index = len(df) // 2
reference_df = df.iloc[:mid_index]
monitored_df = df.iloc[mid_index:]
It's a good practice to first identify the important features in your dataset. Use data visualization techniques and domain knowledge to determine which features to evaluate for drift. Here, I have selected some columns to evaluate for drift.
columns_to_evaluate = ['Order Date','Ship Mode','Category','Sales']Once the dataset is prepared, we can use the NannyML OSS library to calculate univariate drift. NannyML is a complete monitoring solution that offers a wide range of tools and algorithms to help data scientists detect and manage drift in their machine-learning models.
import nannyml as nml
drift_calculator = nml.UnivariateDriftCalculator(
column_names=columns_to_evaluate,
timestamp_column_name='Order Date',
continuous_methods=['kolmogorov_smirnov', 'jensen_shannon', 'wasserstein', 'hellinger'],
categorical_methods=['chi2','l_infinity','jensen_shannon','hellinger'],
)
When initializing the drift_calculator object, we specify several parameters to tailor its behaviour. The
column_names parameter specifies target columns for drift analysis. If a dataset lacks a timestamp column, then evaluation happens using the index. Here, the Order Date column is set for the timestamp column because it marks the beginning of customer interaction. The continous_methods and categorical_methods allow us to specify all methods in a list. To know more, check out our tutorial with a detailed explanation of hyperparameters. drift_calculator.fit(reference_df)
results = drift_calculator.calculate(analysis_df)The
fit method is called to train the drift_calculator using the reference dataset. This step establishes a baseline against which monitored results will be compared. The calculate method detects and quantifies drift on the analysis dataset.In the next sections, we'll explore the all methods available for data drift detection and their respective pros and cons.
Jensen-Shannon Distance
The Jensen-Shannon Distance is a powerful metric for categorical and continuous features. It measures the dissimilarity between two probability distributions by finding the amount of overlap between them. It is a proper distance metric that can be defined as the square root of the Jensen-Shannon divergence. It is a symmetric version of the Kullback-Leibker (KL) divergence and is bounded between 0 and 1 to make it more stable and interpretable.
Steps to calculate drift:
- Bin the continuous feature values to discretize them. If the feature is categorical, we don't need to bin the data because each unique category is already a "bin" in itself. Calculate the probability density functions (PDFs) for the reference and monitored data. Compute the mean of the PDFs for each bin to create an average distribution.
- To obtain the JS divergence, you average the KL divergences between the reference and monitored distributions and their average distribution.
- The JS Distance is the square root of the JS Divergence. This makes the measure symmetric.
The mathematical formula :
figure1 = results.filter(methods=['jensen_shannon']).plot(kind='drift')
figure1.show()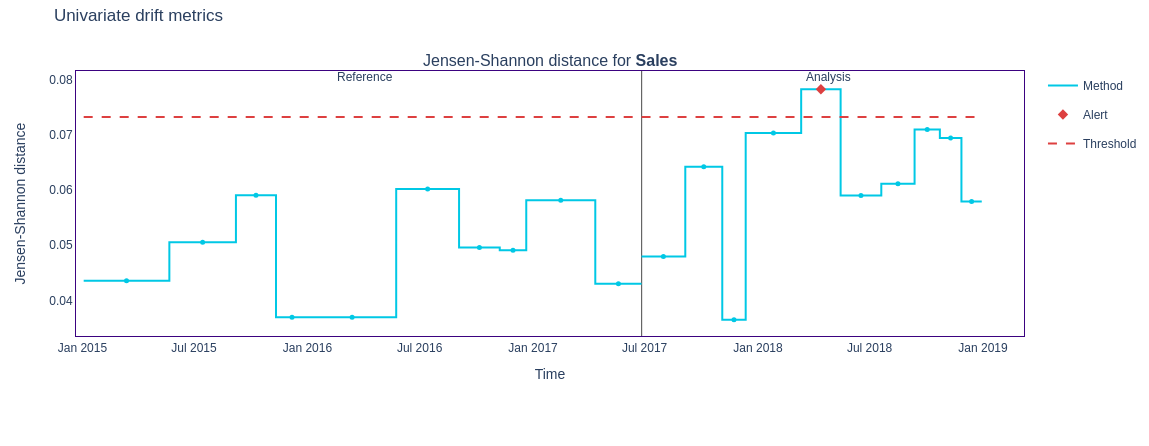
The
result.filter method allows for filtering the results based on specific criteria, such as methods used for drift calculation. In the code snippet above, methods=['jensen_shannon'] filters the results to include only those obtained using the Jensen-Shannon method.We can even filter by columns like this :
figure2 = results.filter(column_names=results.['Category'], methods=['jensen_shannon']).plot(kind='drift')
figure2.show()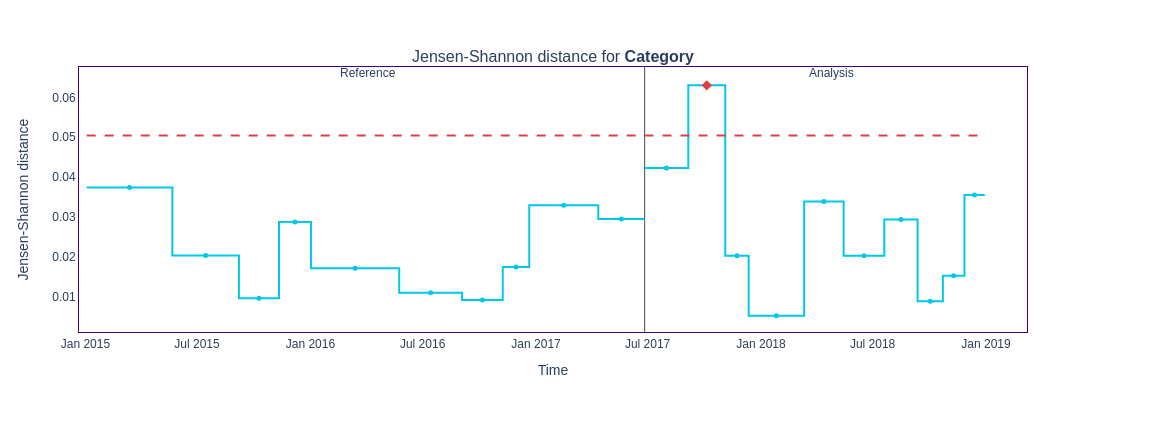
The plot displays the feature distributions instead of drift metrics by changing the
kind parameter to ‘distribution’. figure3 = results.filter(methods=['jensen_shannon']).plot(kind='distribution')
figure3.show()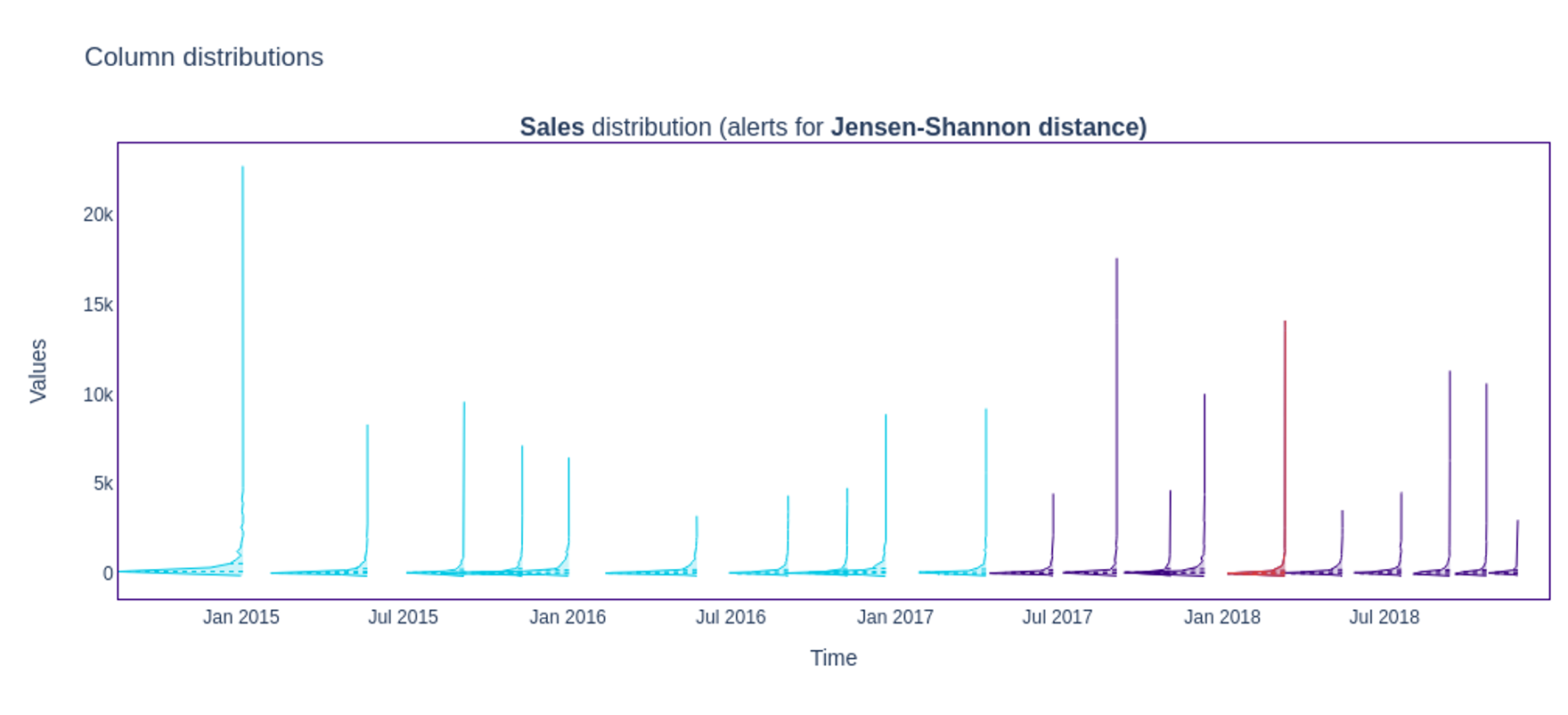
Pros:
- Provides a true metric, satisfying properties like symmetry and triangle inequality.
- Bounded between 1 (maximum dissimilarly )and 0 (identical).
- It is relatively more sensitive to smaller shifts than bigger ones. This means that a shift in the mean of the analysis data set from 0 to 0.1 will cause a more significant change than a change from 5.0 to 5.1.
Cons:
- Does not differentiate between very strong and extreme drifts.
- Computationally intensive for large datasets.
- In cases with many categories, it can be difficult to detect a significant shift if it only occurs in a few categories. Sampling effects can cause small differences in the frequency of each category, but when summed together, these small differences can hide important changes that occur in only a few categories.
Hellinger Distance
The Hellinger Distance measures the distance or overlap between two probability distributions. A smaller distance indicates a greater overlap (less drift), while a larger distance indicates less overlap (more drift). It is versatile and applicable to both continuous and categorical features because it fundamentally measures the overlap between two probability distributions, regardless of the type of data being analyzed.
Steps to calculate drift :
- For categorical features, we use the frequencies directly to calculate PMF. In the case of continuous data, we convert it into a histogram to create a PDF and then compute the Hellinger Distance using the bin probabilities.
- The Hellinger distance between two distributions 𝑃,𝑄 for a categorical feature as:
- A smaller distance means a smaller drift.
figure4 = results.filter( methods=['hellinger']).plot(kind='drift')
figure4.show()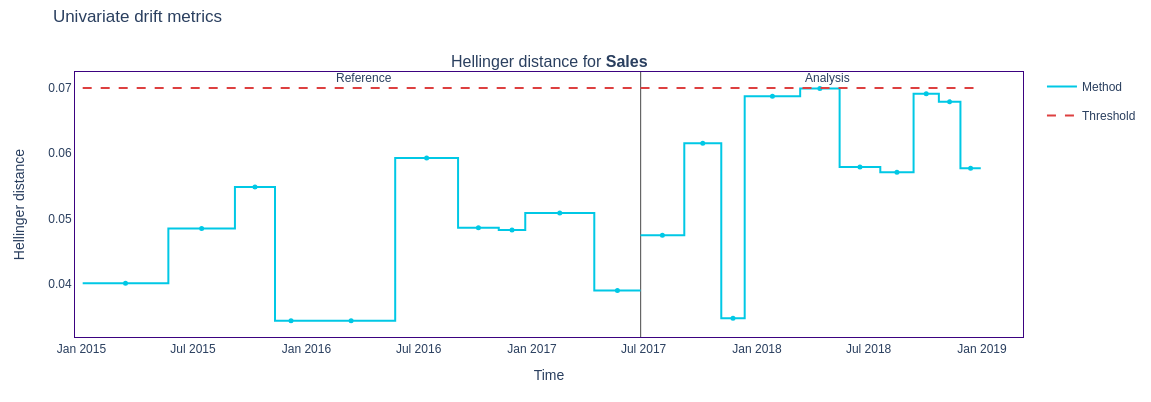
Pros:
- Recommended to use in case of medium shifts
Cons:
- Breaks down in extreme shifts
- In cases where the amount of overlap stays the same but drift increases, neither the JS nor Hellinger distance will detect the change.
Kolmogorov-Smirnov Test
The Kolmogorov-Smirnov (KS) test determines if two samples come from one continuous distribution. It is a nonparametric statistic test useful for comparing the distributions of one-dimensional continuous data.
The KS test evaluates the maximum vertical distance between the empirical CDFs of two samples. This distance represents the largest discrepancy between the cumulative probabilities of the two samples at any point along the x-axis.
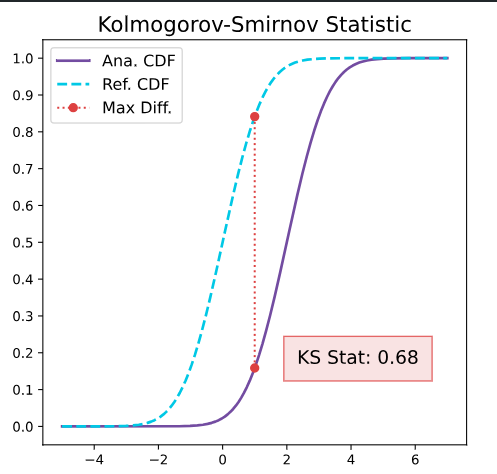
How is drift calculated:
- Calculate the empirical cumulative distribution functions (CDFs) for reference and monitored datasets.
- Identify the maximum distance between the two CDFs, known as the D-statistic. Use the D-statistic to compute the p-value under the null hypothesis (that both samples come from the same distribution).
- For datasets with fewer than 10,000 rows, NannyML uses the reference data directly for comparison. For larger datasets, the continuous feature is split into quantile bins, utilizing the bin edges and frequencies, reducing memory usage and computational overhead.
figure6 = results.filter( methods=['kolmogorov_smirnov']).plot(kind='drift')
figure6.show()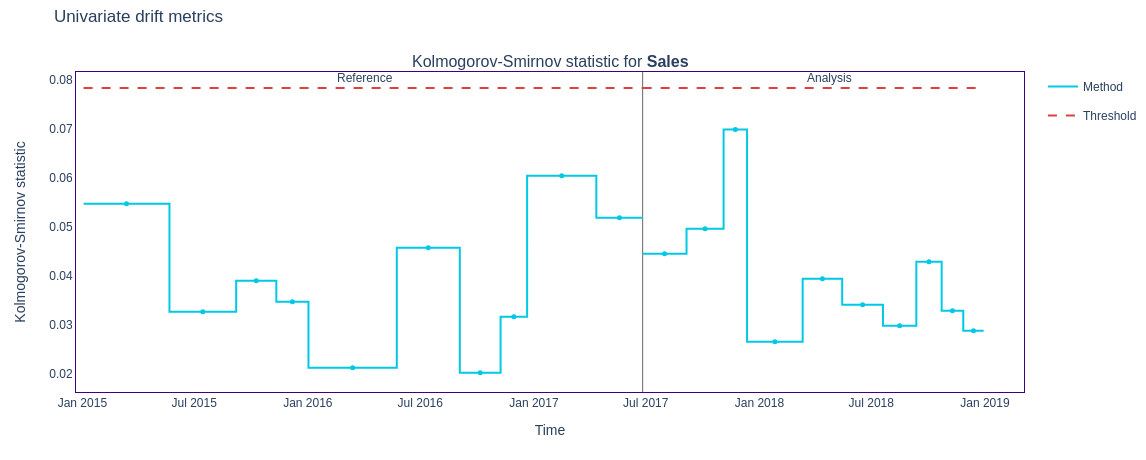


Pros
- The D-statistic falls within a 0-1 range, making it straightforward to interpret.
- The D-statistic is robust to small changes in data, making it reliable for monitoring data distributions.
- The test does not assume any specific distribution, making it versatile.
Cons
- May miss local drifts in distribution tails.
- The test is sensitive to sample size, which can lead to false alerts.
Wasserstein Distance
The Wasserstein Distance represents the minimum amount of "work" required to transform one distribution into another, where "work" is defined as moving mass between points. It can be reimagined as the amount of "earth" (probability mass) that needs to be moved to transform one "pile" (distribution) into another, hence the name Earth Mover Distance. The distance is the total cost of the optimal transport plan. It uses the Cumulative Distribution Functions for one-dimensional distributions.
NannyML finds the Wasserstein Distance by comparing the distribution of a feature in the reference dataset against its distribution in successive chunks of the analysis dataset.
figure7 = results.filter( methods=['wasserstein']).plot(kind='drift')
figure7.show()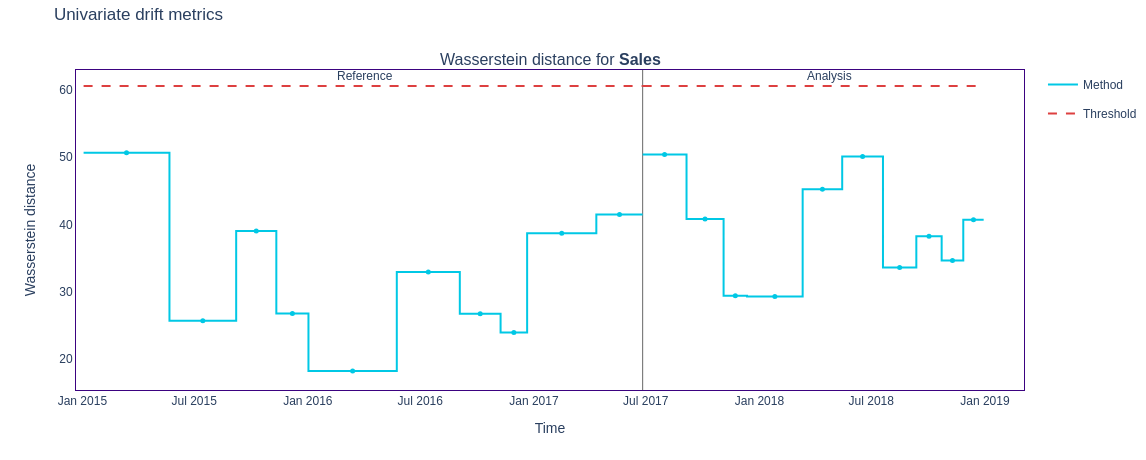
Pros
- Unlike other metrics, it captures the shape and location differences between distributions.
- Provides a true metric, satisfying properties like symmetry and triangle inequality.
Cons
- It is sensitive to extreme values. The JS distance, the KS statistic, and the Hellinger distance are much more stable.
- Computationally expensive for large datasets.
Chi-Squared Test
The Chi-Squaure Test is a popular hypothesis test for determining how independent a feature is. It determines the amount of association between two categorical features in a contingency table. The output of this test is a χ2 statistic and an associated p-value, which helps in deciding whether to reject the null hypothesis of independence.
The observed and expected frequency calculations central to the Chi-Square test's logic do not naturally apply to continuous data. Notably, the Chi-Squared statistic increases with the sample size while the other metrics do not.
Steps for calculating drift using this method:
- Construct a contingency table based on two categorical features from the reference and monitored data.
- Calculate the chi-square statistic by comparing each table sample's observed (xi) and expected frequencies. The difference is squared and divided by the expected frequency, and the resulting value is then summed over all categories for both samples.
- An alert is raised if the resultant statistic value is above the p-value.
figure8 = results.filter(methods=['chi2']).plot(kind='distribution')
figure8.show()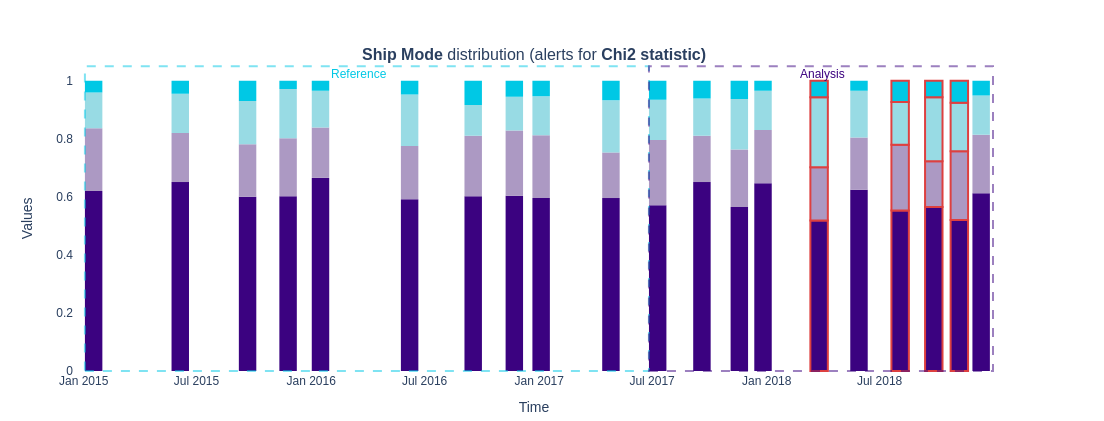
In the analysis period, several bars have a red outline indicating a drift. The drift could impact models that rely on ‘Ship Mode’ as a feature. For example, a model trained to predict shipping costs might affect customer satisfaction or estimate delivery time.
Pros
- It is a common choice among practitioners as it provides a p-value and a statistic that helps to evaluate the result better.
- Shift as measured by JS distance, Hellinger distance, and L-infinity distance decreases as the monitoring sample increases in size. On the other hand, the chi-squared statistic on average remains the same. This behaviour may be considered beneficial in some cases.
Cons
- Not recommended for categorical features with many low-frequency categories or high cardinality features unless the sample size is large.
- The statistic is non-negative and not limited, sometimes making it difficult to interpret.
- When the chunks in your analysis may be different sizes, as can be the case when using period-based chunking, we suggest considering this behaviour before using the Chi-squared statistic.
Traditional ML monitoring looks for data drift, which tends to overwhelm teams with false alarms because not all data drifts impact model performance.
By focusing on what matters, NannyML alerts are always meaningful. Read to find out:

.jpg?table=block&id=89aa7769-6df9-4684-9145-3896b34cd427&cache=v2)
L-Infinity Distance
The L-infinity distance, also known as the Chebyshev distance, finds the maximum absolute difference between the corresponding elements of two distributions. It is the largest vertical gap among all the comparisons in the figure below. This maximum gap represents the most significant change in category frequency, clearly indicating where the largest drift has occurred.
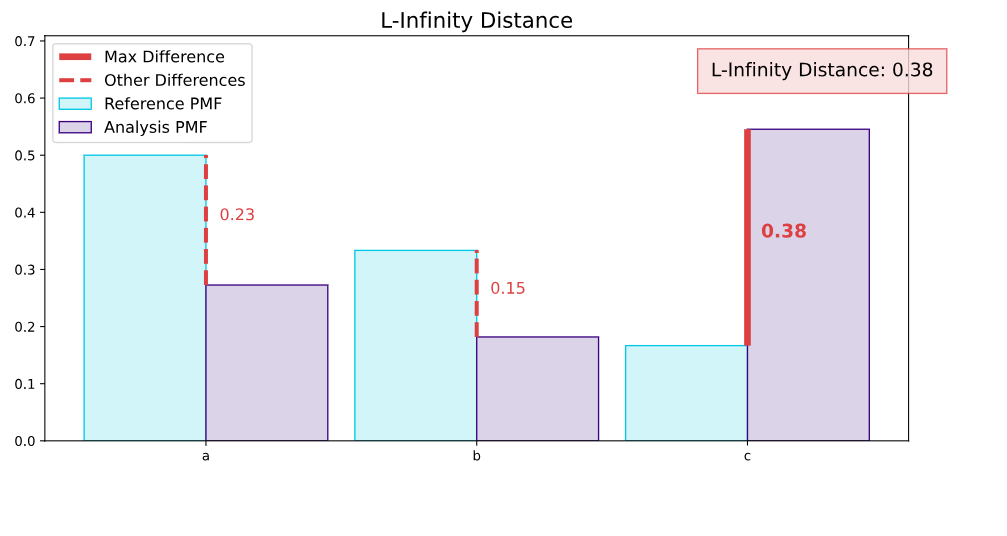
figure10 = results.filter(methods=['l_infinity']).plot(kind='drift')
figure10.show()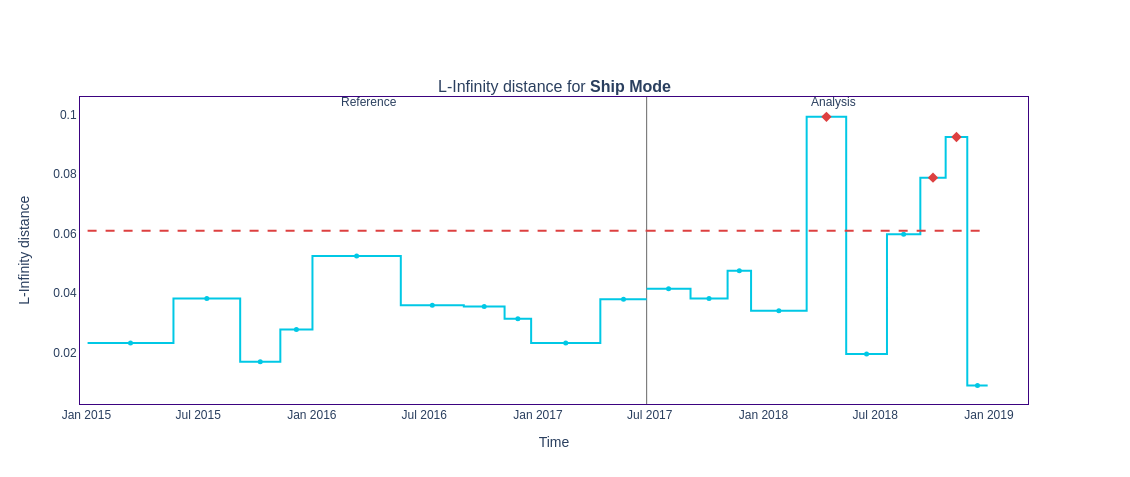
You can extract the distance for a specific feature and examine them in a dataframe.
l_infinity_scores = results.filter(period='analysis' , methods=['l_infinity']).to_df()
l_infinity_scores['Ship Mode']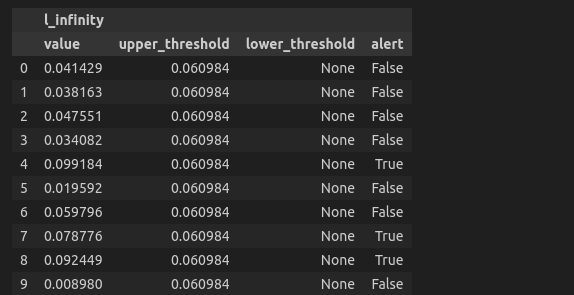
An alert is raised if the L-infinity value exceeds the upper threshold. This indicates that the feature distribution has changed substantially compared to the reference period, and further investigation or action may be required.
Pros
- Highlights the most significant change in category frequencies
- Quick computation, making it suitable for large datasets
- When dealing with data sets with many categories, using the L-infinity distance may help to reduce false-positive alerts.
Cons
- May overlook smaller but significant cumulative changes across several categories
Conclusion

There is no need to stress; here is a table summarizing the contents of this blog for later reference:
Method | Continuous | Categorical | Pros | Cons | Uniqueness |
Jensen-Shannon | ✅ | ✅ | Provides a true metric, stable, interpretable | Computationally intensive for large datasets | Symmetric properties |
Hellinger | ✅ | ✅ | Captures small distribution changes | Sensitive to binning method choice and breaks down in extreme shifts | Measures overlap effectively |
Kolmogorov-Smirnov | ✅ | ❌ | Robust to minor fluctuations, nonparametric | May miss local drifts in distribution tails | Focuses on maximum CDF differences |
Wasserstein | ✅ | ❌ | Work as a shift measure
is relevant | Sensitive to outliers | Unlike other metrics, It captures the shape and location differences between distributions. |
Chi-Square | ❌ | ✅ | Commonly used, provides p-value and statistic | Requires large sample sizes. Sensitive to small expected frequencies | Focuses on expected vs observed frequencies |
L-infinity | ❌ | ✅ | Quick to compute, highlights significant changes | Less informative for complex distributions | Suitable for detecting large, obvious drifts |
Are you confident that your model is performing at its best? Data drift can silently degrade your model and your business impact. But don't worry—there's a solution! Monitor your models post-production. Built around a performance-centric workflow, NannyML Cloud lets you monitor what truly matters, find what is broken, and fix any issue. Schedule a demo to learn how NannyML can be the game-changer your data science team needs.
FAQ section
What are the best methods to detect univariate data drift?
The best method to detect univariate data drift depends on the feature type. Methods like Kolmogorov-Smirnov and Wasserstein are used for continuous features. They compare feature distributions over different periods to identify drift. For categorical features, Chi-Sqaure and L-Infinity analyse the frequency distributions of categories. Jensen-Shannon and Hellinger Distance methods can be used for continuous and categorical features.
How do we monitor data drift in continuous features?
Key methods for detecting drift in continuous features include Kolmogorov-Smirnov, Wasserstein, Jensen-Shannon, and Hellinger. These methods identify deviations by comparing the feature's distributions across periods.
How do we monitor data drift in categorical features?
Chi-square and L-infinity tests are useful for tracking data drift in categorical features. The Chi-square test checks the independence of two distributions to identify frequency changes. Meanwhile, the L-infinity test calculates the largest difference between empirical distributions of categories.
Written by
