
A data scientist's job continues after the model is deployed to production. Unfortunately, many things can go wrong in an ML system. One of them is model performance degradation.
It's natural for ML models to degrade - a recent study published in Nature journal found that 91% of AI degrade in time. Degradation happens because ML models are part of a constantly changing dynamic system. For example, a business opening a new location, introducing a new product, or changing the economic environment can make ML models fail.
91% of AI degrade in time
This is one of the differences with traditional software development, where developers carefully design a deterministic solution and program how the system will react to any request. So engineers typically monitor operational system metrics such as uptime, latency, number of requests, etc.
On the other hand, when it comes to Machine Learning Systems, the solutions we develop are typically not deterministic. Machine learning models are probabilistic solutions that data scientists build with the context and biases of a training dataset. So, when the production data no longer resembles the training data, the ML model can start to degrade. And, since probabilistic solutions make mistakes by design. It is challenging to differentiate between an expected error and one occurring because something more fundamental is going wrong.
This is why for monitoring machine learning systems is not enough to only track operational system metrics. We also need to monitor how the model behaves with production data.
The traditional way of monitoring
Broadly speaking, companies have typically monitored their ML models by doing two things, measuring the realized model performance and checking for signs of data drift. This makes traditional monitoring solutions to be centered around alerting for data drift and having visibility of the model's performance only when we have collected newly labeled data.
Let's expand on both of these methods and learn more about their limitations.
Measuring Realized Performance (if you can)
To measure the realized performance of a production ML model, we need to collect production data and manually label it or wait until the ground truth is available. After that, we can compare the labels with the predictions and calculate the realized performance. If this performance is very different from the test performance, we have strong indications of model degradation.
One limitation of monitoring an ML model by measuring the realized performance is that we need labeled data. In problems like loan detection targets are often delayed while in others labels are completely absent and we may need to manually label many examples to build a representative sample. This process takes time, and as Goku Mohandas put it well in his Monitoring Guide:
If we wait to catch the model decay based on the (realized) performance, it may have already caused significant damage to downstream business pipelines that are dependent on it.
Alerting Data Drift
Data distribution drift is one of the main causes of ML model failures. Data drift happens when the distribution of the production data differs from the model's training distribution. This can happen due to a large number of reasons. For example, a model being used in a new market, economic or environmental factors modifying people's behaviors, etc. Models that have not observed this type of behavior in the historical data might degrade with time and make less reliable predictions.
.avif)
We can detect data drift by applying statistical tests to samples from the training and production data. These methods are very useful for understanding the nature of the drift, but as we are going to see shortly, data drift detection should not be at the center of our monitoring solution.
Some systems monitor ML models by measuring the difference between distributions and firing an alert every time a drift above a certain threshold is observed. In principle, this may sound like a good approach. But this method assumes that every drift is going to affect the model's performance. While in reality, this is not always the case.
A feature can be drifting, but if it is not very relevant in terms of feature importance, the model’s performance may remain unchanged. Another limitation is that these statistical methods are often very sensitive. They require a lot of experimentation and know-how from the data science team to choose the correct statistical test, as well as set up the correct alert thresholds. Otherwise, we could be alerting for changes in distribution that are not relevant.
Having drift detection at the center of an ML monitoring system can do more harm than good. Since it may overwhelm the team with too many false alarms, causing alert fatigue.
Alert fatigue is a phenomenon where the data science team is exposed to too many alerts that they end up not paying attention to them. Alert fatigue can cause us to miss relevant alerts since we are surrounded by the noise coming from all the other false alarms.
The new ML monitoring workflow in town

NannyML obsesses over performance. Model performance and business impact are at the core of this monitoring flow. At the end of the day, performance is what matters the most.
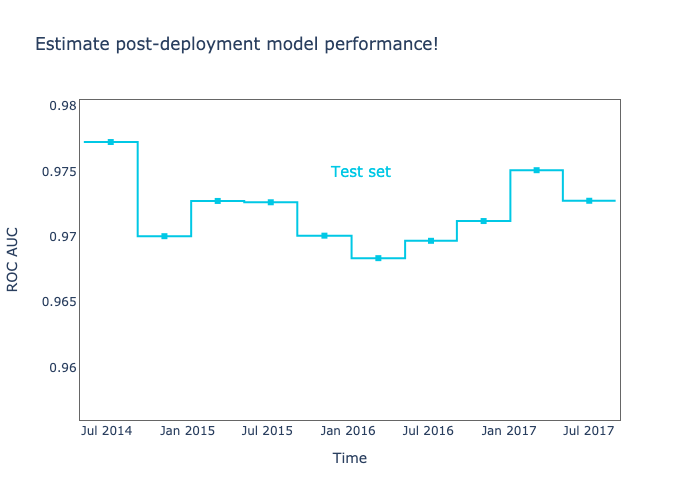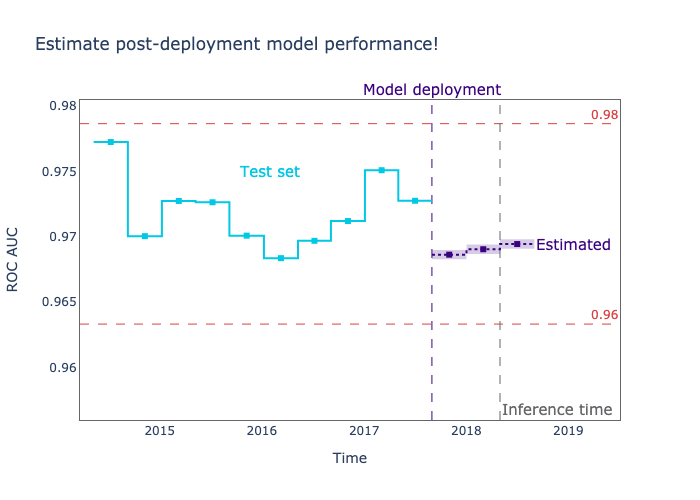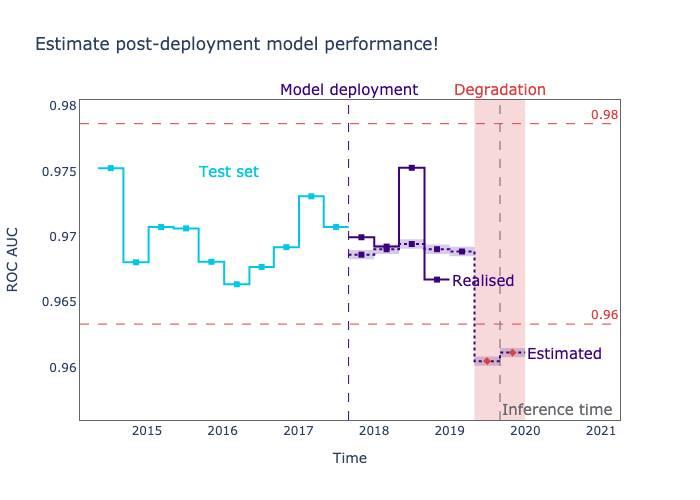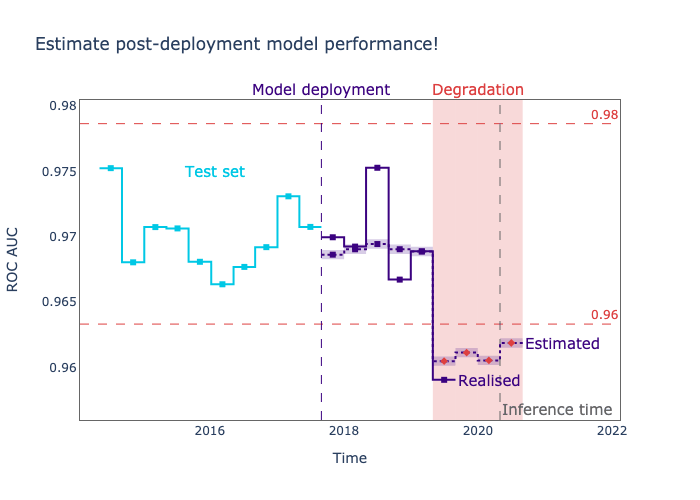
Imagine you could use probabilistic methods to estimate model performance and don't have to wait for the ground truth to come in to know how your model is doing. Wouldn’t it be great to monitor the ML model's performance in real-time like that? Well, that’s why NannyML developed novel probabilistic algorithms to estimate the model's performance even when targets are not available.
This allows us to babysit the ML model's performance at all times. And alert the data science team only when performance degradation is found. This way, we become less reliant on data drift. Yet, data drift still has its purpose. Instead of using it as an alerting system, it can be leveraged for searching plausible explanations of the underlying issue.
This monitoring flow gets rid of the overload of false alarms, enabling us to focus on the ones that matter.
.avif)
Monitoring Estimated Performance
Estimating performance is a superpower. We no longer need to wait for the ground truth to have visibility on how an ML model is performing with production data. Probabilistic methods such as CBPE (Confidence-based Performance Estimation) and DLE (Direct Loss Estimation) allow us to estimate the performance for classification and regression models, respectively. It’s important to be aware that since these methods are probabilistic, they can make mistakes too. They are known to deal with data drift very well, but dealing with concept drift is still an open research question that we at NannyML are working to answer.
Depending on the task and business requirements, we can leverage these methods to estimate the performance on a daily, weekly, monthly, or any other time basis. By periodically monitoring estimated performance, we stay ahead of the curve and monitor what really matters.
In this new workflow, performance monitoring is at the core of the workflow. We no longer use data drift as an alerting system. The system fires an alert only if it observes a drop in the estimated performance.
Root Cause Analysis
If a drop in performance is observed, we can perform a Root Cause Analysis (RCA) using data drift detection mechanisms. Multivariate and univariate drift detection methods are tools that data scientists can use to investigate if the model degradation was caused by covariate shifts and identify which features are responsible for the performance drop.
When applied correctly (and not as an alarming system), these tools can help us find plausible explanations for the performance drop and have a better understanding of the limitations of our ML systems.
For example, below we have a regression model that has been underperforming since November.
After the data science team got the alert, they performed a root cause analysis, searching for plausible features that may have been causing the performance drop. After applying univariate drift detection methods, they found that a relevant feature has been drifting in the same period where the model has been underperforming.
.avif)
On the other hand, this other feature drifted once during the month of October (outside of the degradation region). If we were using data drift as a monitoring system, we would have been alarmed about this. But it was a false alarm since no performance degradation occurred during that period. This drift did not cause any performance degradation because it has a low feature importance for the model.
Issue Resolution
Once we have found the underlying cause of the performance issue, we can search for the best technique to fix the problem. The appropriate solution is context-dependent, there is no simple fix that fits every problem.
Depending on the type of issue and severity of the alert there are some things that can be automated and others may require more work. The most common solutions are gathering more data and retraining your model, reverting your model back to a previous checkpoint, fixing the issue downstream, or changing the business process.
To learn more about when it is best to apply each solution check out our previous blog post on How to address data distribution shift.
Conclusions
We learned about the limitations of the traditional ML monitoring workflow, where data drift detection is at the center of the system. We also introduced a new monitoring workflow in which we obsess over performance and leverage probabilistic methods to estimate model performance even when the ground truth is not available. And use drift detection methods as tools to find plausible explanations for the model performance issue.
If you want to learn more how to use NannyML in production, check out our other blogs and docs!
Also, if you more into video content, we recently published some YouTube tutorials!
Lastly, we are fully open-source so don’t forget to star us on Github! ⭐








.avif)