.jpg?table=block&id=68890156-8cfa-495c-9eb9-1eda8c8d1b1d&cache=v2)
Do not index
Canonical URL
Introduction
Machine Learning models get deployed to production when they perform well enough to provide value. Performance is all that matters, so it has to be carefully monitored post-deployment. When labels are available right after prediction, it can be just calculated. But labels are either delayed or not available at all. To deal with this, mature data science teams will monitor the changes in input data distribution and treat it as an indicator of model performance stability.
The problem is that data drift happens constantly, often without negatively impacting performance. The methods that measure input data drift magnitude cannot quantify that impact accurately, even if combined into complex models. We know it because we tested it. And because of that we research and develop algorithms that can do better.
In this article, I will explain the intuition behind the Probabilistic Adaptive Performance Estimation (PAPE) algorithm, which can estimate the performance of classification models without labels, under covariate shift. I will show how it relates to its predecessor - Confidence-based Performance Estimation (CBPE).
Setting up an example
First, let’s briefly recap data drift and covariate shift and then describe a simplified machine learning problem that we will use as an example.
Pure covariate shift is a change in the joint probability distribution of input variables provided that the concept, that is, the probability distribution of targets
conditioned on inputs , remains the same. The example we will work on is a credit default model (binary classifier) that uses only one continuous feature - credit applicant’s income. So in our case , and . Since we have a binary classification problem, the target can take only two values: 0 or 1. Since it is enough to analyze only one of those. We will focus then on because it is intuitive - it is the probability that the credit applicant will default given its income. We call this a concept.
For the case analyzed, input distribution and concept can be easily visualized:
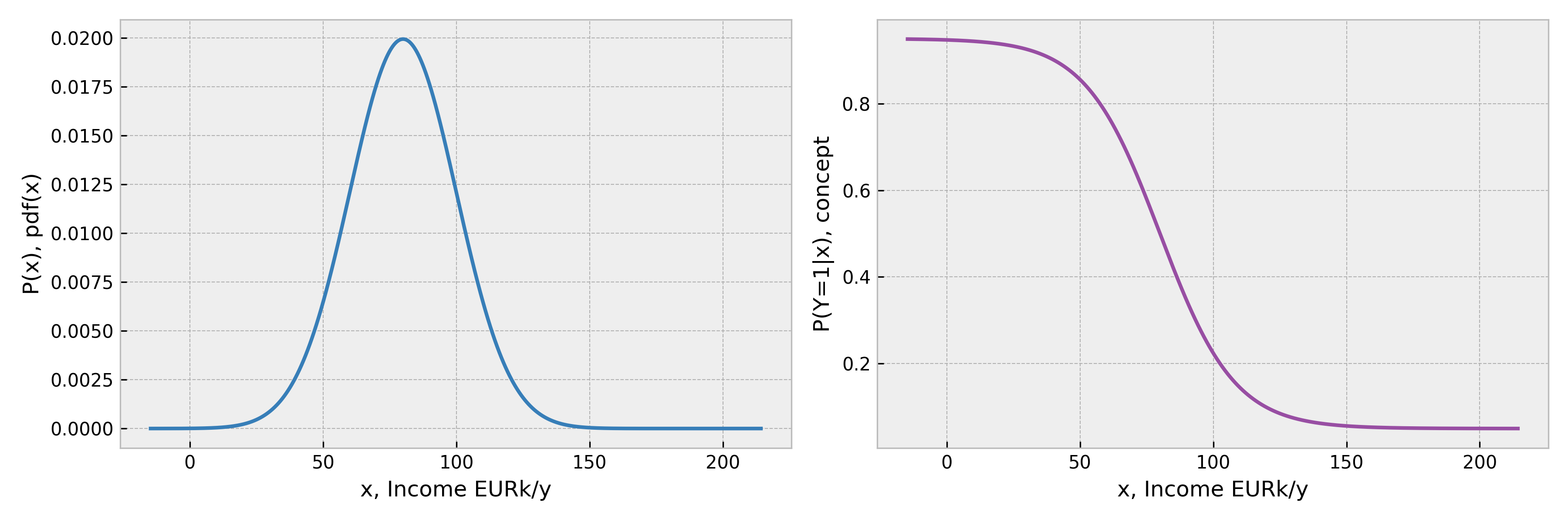
So, the initial, or the reference, situation is the following.
We have a normally distributed input with a mean annual income of around 80 kEUR. The true concept assigns ~ 95% probability of defaulting for applicants with 0 income, and that probability sigmoidally drops, converging to 5% for applicants with income above 200 kEUR. It reaches a 50% defaulting probability at around 80 kEUR.
Now, these two plots describe the data generation process - they provide a so-called oracle knowledge about the modeled phenomenon. In reality, the true concept is unknown, but it is often well approximated by the model. In fact - this is what classification models try to learn.
For example, a trained sklearn classifier holds a representation of the learned concept, which maps inputs to label probability estimates through the predict_proba method. The output of the predict_proba method is sometimes called a score or a predicted probability - from now on we will use the latter term. A classifier is just a function so we will call it and the predicted probability it returns is . The predicted probability approximates the true concept so .
Let’s assume that the investigated model does it pretty well. Figure 2 shows the true concept and its learned approximation (a classifier’s predicted probability). We see that the classifier underestimates the probability of defaulting for low-income and overestimates it for high-income applicants. This could be the case in reality because from the input data distribution, we see a relatively low probability of observing data from these regions, so they are harder to learn.
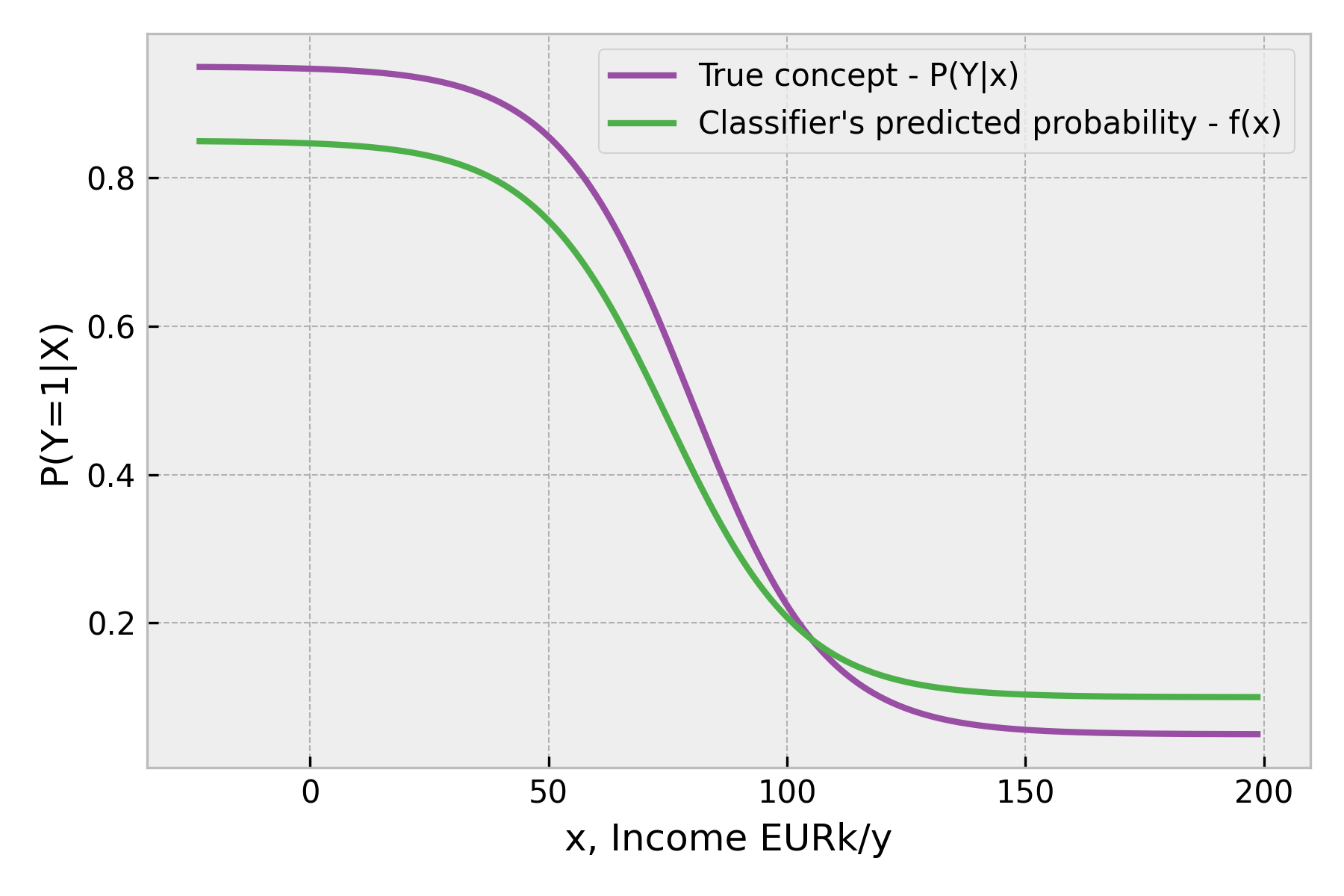
Usually, predicted probabilities returned by the classifier are turned into actionable binary predictions by thresholding. Let’s define a threshold function that returns binary predictions so that , and when and otherwise. We will need this to estimate/calculate performance metrics that use binary predictions (like the accuracy score).
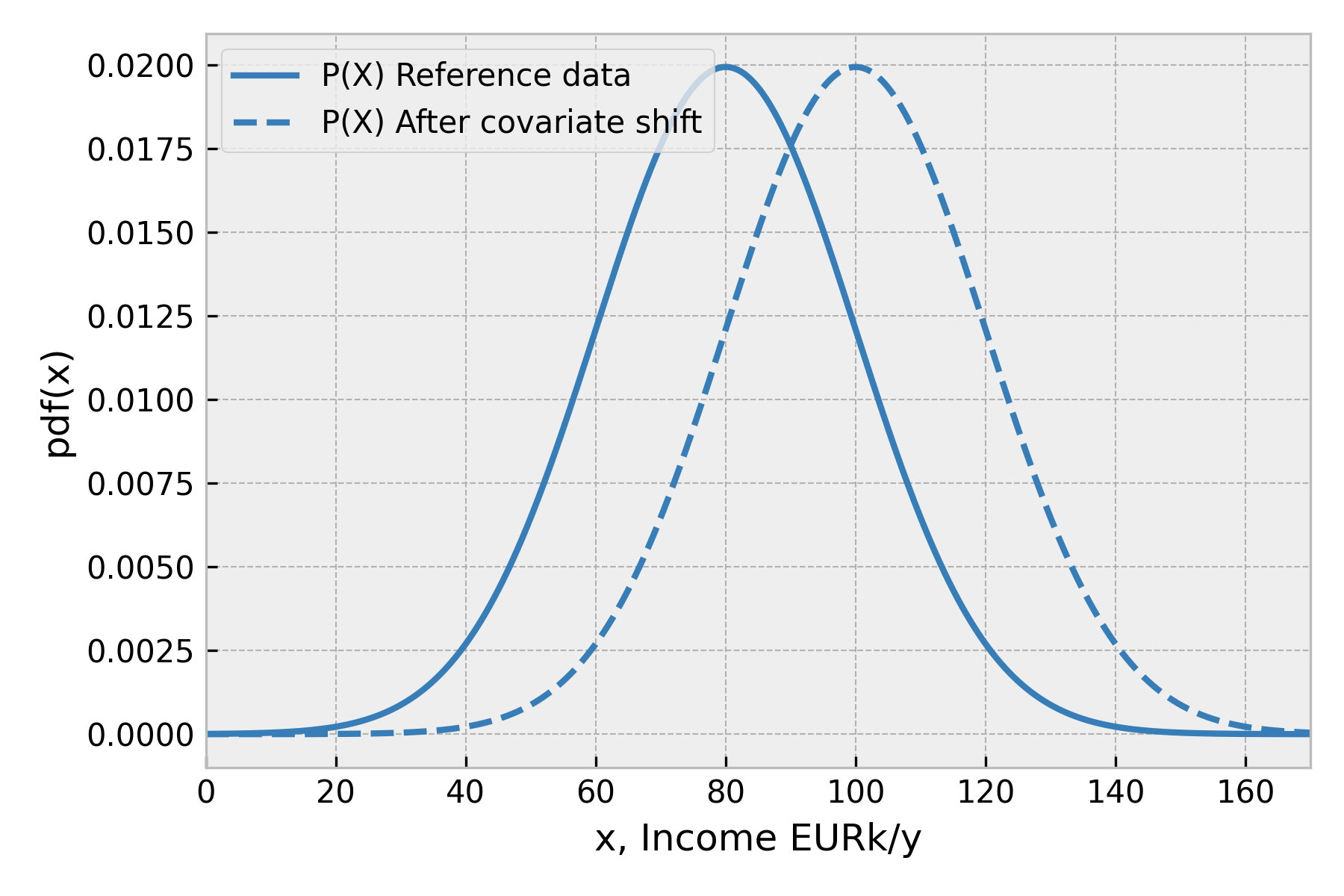
Finally, let’s simulate a pure covariate shift. Following the definition, only the distribution of inputs changes; the true concept remains the same, and model scores and predictions conditioned on input do not change. Figure 3 shows the change in the input data distribution we will further analyze.
Alright, we have the basic definitions, notation, and the whole example sorted out. Now, a short teaser on how performance can be estimated with a confidence-based, probabilistic approach, and then we go deep into details.
Teaser on probabilistic performance estimation
The predicted probability returned by a classifier represents its confidence in the prediction. High-confidence estimates (close to 0 or 1), are more likely to be correct than low-confidence estimates (close to 0.5). That is the intuition behind confidence-based approaches to performance estimation.
To make accurate estimates of performance metric values, we need more than predicted probabilities - we need calibrated probabilities. A predicted probability is a calibrated probability when… well when it is a probability—a probability of observing a positive label. In practice, calibrated probability simply corresponds to the relative frequency of positive targets (also called fraction of positives).
So when a calibrated model returns a probability of 0.9 for a set of observations, exactly 0.9 of those observations ends up with a positive label. Assuming the binary prediction is also positive (1), 0.9 predictions will end up correct, while 0.1 will be incorrect. This means we will see a True Positive prediction 90% of the time and a False Positive for the remaining 10% of the observations. This also corresponds to the accuracy score of 0.9. Simple enough. Let’s go deeper.
Calibration
The definition of calibration from a few sentences ago is the most popular, practical view of it. You may have gotten confused because we used to talk about probabilities of observing positive targets, and suddenly, we spoke about the relative frequency of positive targets. Let’s see where it comes from.
On the distribution level, a predicted probability returned by a model is calibrated when it is equal to the probability of observing a positive label (conditioned on that predicted probability). Using math we write it as: .
The probability of observing a positive target conditioned on predicted probability is equal to the expected value of a target conditioned on that same thing, that is .
Moving from theory and distributions to practice and data - the expected value of target conditioned on can be just approximated by calculating relative frequency of positive targets (or a mean of target) for all the observations with predicted probability equal to , so .
This takes us directly to the definition we introduced: a predicted probability is considered a calibrated probability when it corresponds to the relative frequency of positive targets. With language of math: .
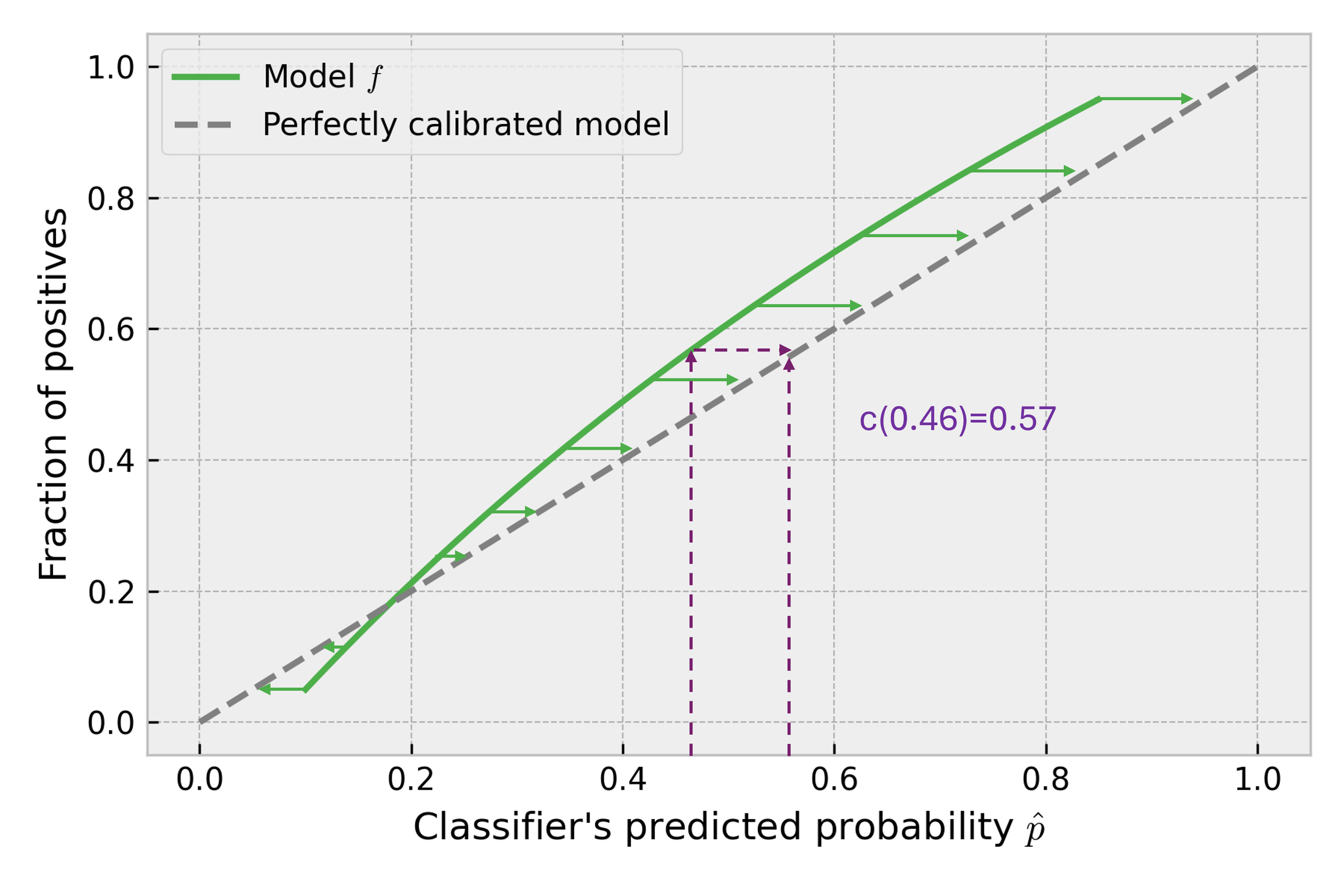
Now, let’s evaluate the quality of calibration of the analyzed classifier by plotting the calibration curve that shows the fraction of positive targets for all possible values of predicted probabilities :
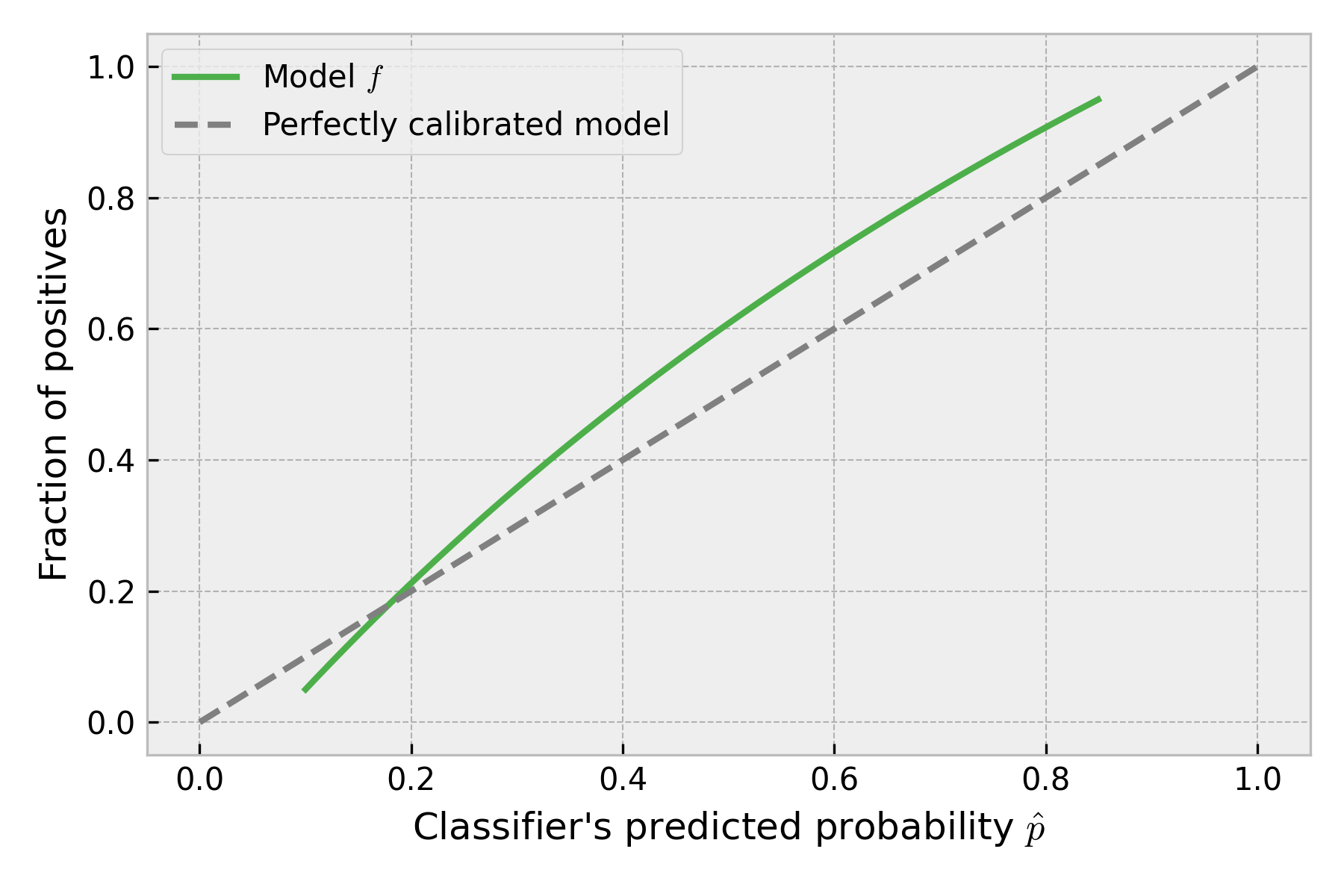
Now, we see that the model overestimates the score for predicted probabilities below 0.2 (which correspond to high incomes) and underestimates it for the rest of the predictions. It is calibrated only for the , which can be seen also in Figure 3 (intersection of the curves).
Notice how values of do not cover the entire range between 0-1, that is expected since the model never predicts probability lower than 0.1 or higher than 0.85 (see also Figure 2). Such a smooth calibration curve is not easy to obtain and requires a lot of data. That is because we have to calculate the fraction of positive targets (the mean of targets) for each . We need hundreds of labeled observations for each possible model predicted probability to make it reliable. Sometimes we have only one. For some values of we don’t have any - the model simply never predicted it. That’s why, in practice, similar predicted probabilities are grouped into bins, and the fraction of positives is calculated for a bin. For clarity, simplicity, and better plots, we will stick to the infinite data example, though.
Notice how, until now, we talked about calibration conditioned on model predicted probability . We focus on it because it is what we require to estimate performance accurately. There are other levels of calibration, though. The strongest calibration for a particular model is calibration conditioned on the model’s inputs. Then we expect that . In other words, we expect the classifier to be Bayes optimal classifier. We expect it to return the true positive target probability for every possible input value. Achieving this calibration level makes the classifier automatically calibrated conditioned on the predicted probabilities, as well.
A classifier can also be calibrated conditioned on some specific groups of inputs. So, it does not have to return a calibrated probability for each possible input. It is enough if it matches the positive target fraction when averaged across an identified group of inputs (for example - credit default applicants with income between 80-100 kEUR/y). This may or may not correspond to calibration conditioned on model-predicted probabilities.
Finally, there’s the weakest calibration: the mean model predicted probability must equal the fraction of positive targets (class balance) without conditioning on anything. We just write it as .
Estimating performance without labels with CBPE
Let’s get back to the main topic. We already know that when we have calibrated probabilities, we can estimate a performance metric without labels. CBPE exactly does that.
First, it takes the raw predicted probabilities from a classifier and calibrates them. In fact, it fits a calibrator that is simply a regressor trained on uncalibrated classifier predicted probabilities as inputs and labels as targets. So now, the calibrator takes uncalibrated and turns them into calibrated probabilities, which we write as: . Figure 5 shows how the calibrator updates the raw predicted probabilities.
So, the calibrator fixes the underestimation in a high-probability region, for example, . It does nothing when the raw predicted probability turns out to be calibrated (). It also fixes overestimation in the low-probability region. Notice how the predicted probabilities were limited to a range between 0.10 - 0.85 while the calibrated probabilities lie within 0.05-0.95, corresponding to the true concept range (Figure 2).
First, we will estimate performance for the reference distribution. I have already provided simple intuition: if the calibrated probability for a set of observations is equal to 0.9 and the binary prediction is positive, then we expect to see True Positives (TP) 90% of the time and False Positives (FP) the remaining 10%. It’s similar with negative predictions, that is when . Say that we have a calibrated probability of 0.2 and a negative binary prediction for a set of observations. We will observe True Negative (TN) 80% of the time and False Negative (FN) 20% of the time. Surprisingly, you don’t need a set of observations with the same predicted probability to make use of it. It also holds for a single observation. So a single observation with calibrated probability of 0.9 and positive prediction is expected 0.9 TP and 0.1 FP at the same time. With realized performance, you probably got used to the fact that the number TPs or FPs can only be an integer, but with the probabilistic approach, we estimate the expected values, so it does not have to be. The expected confusion matrix elements for a single observation are:
- When prediction is positive, that is :
- When prediction is negative, that is :
If you want to estimate the number of True Positives for the whole sample you just sum the per-observation expected values. That is correct because the sum of expected values is equal to the expected value of the sum of random variables, regardless of their dependency. Notice one important thing - the raw predicted probability is used to get the binary prediction (with function), but the calibrated probability is used to estimate the expected performance. It makes it interesting for the case highlighted in Figure 5. When the prediction is negative as , but the calibrated probability indicates that positive label is more probable. So we expect this to be FN with 0.55 and TN with only 0.45.
With the expected values of confusion matrix elements, we can easily estimate other metrics, such as precision. From now on, however, we will stick to the accuracy score - it is the simplest metric and makes everything intuitive and easy to understand. We could estimate accuracy from confusion matrix elements (as TP+TN divided by the number of observations), but we can also use a more mathematically elegant approach. An approach that is general and relevant for multiple other metrics as well. Let’s introduce it while comfortably keeping the accuracy score in mind. The accuracy score for a single observation is equal to 1 when the prediction matches the label or 0 otherwise. Let’s denote the accuracy metric as . It takes two inputs: label and prediction, that is . For single observation we know that , and . How to use probabilities here? Let’s take a single observation for which model’s binary prediction is positive. Two things can happen: the label can end up being 1 or 0. Having the calibrated probability, we can tell how likely each outcome is. So the expected accuracy for that observation is simply value of the metric for one outcome (label positive) multiplied by the probability of observing that outcome, plus the metric for the other outcome (label negative) times probability of the other outcome realizing. Long sentence, short equation: for single score that determines binary prediction and calibrated score , we have*:
That is true because we have calibrated probabilities, so it corresponds to:
Let’s calculate it for some arbitrary observation from our example. We have predicted probability , so the binary prediction is 0. The calibrated probability happens to be almost the same so . Using the equation, we get:
We can nicely visualize the value of the expected metric for each possible :
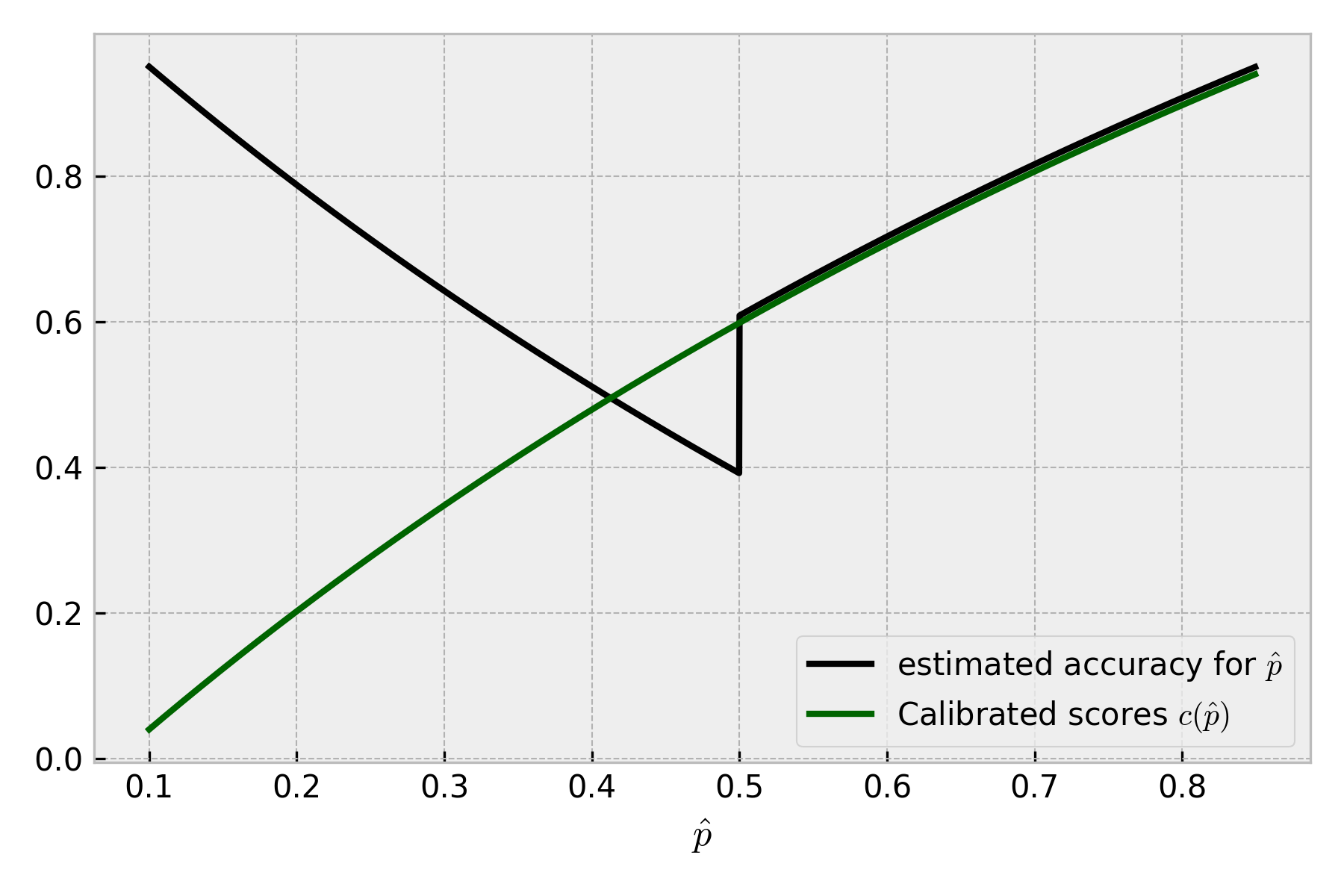
Let’s discuss it. Left to the binary prediction threshold () the prediction is negative, so the expected accuracy is . Right to the threshold, it is positive, and the expected accuracy is . The step change at is caused by the change of binary prediction. If the model were calibrated, the expected per-observation accuracy curve would be smooth and never drop below 0.5. This means a calibrated model with a 0.5 threshold cannot have an accuracy metric lower than 0.5!
To estimate the metric for the whole sample of data, we need to consider the distribution of different values of . With full knowledge of the data generation process (oracle knowledge) we have access to the probability density of inputs, so we also know the probability density of . Let’s put it on that plot.
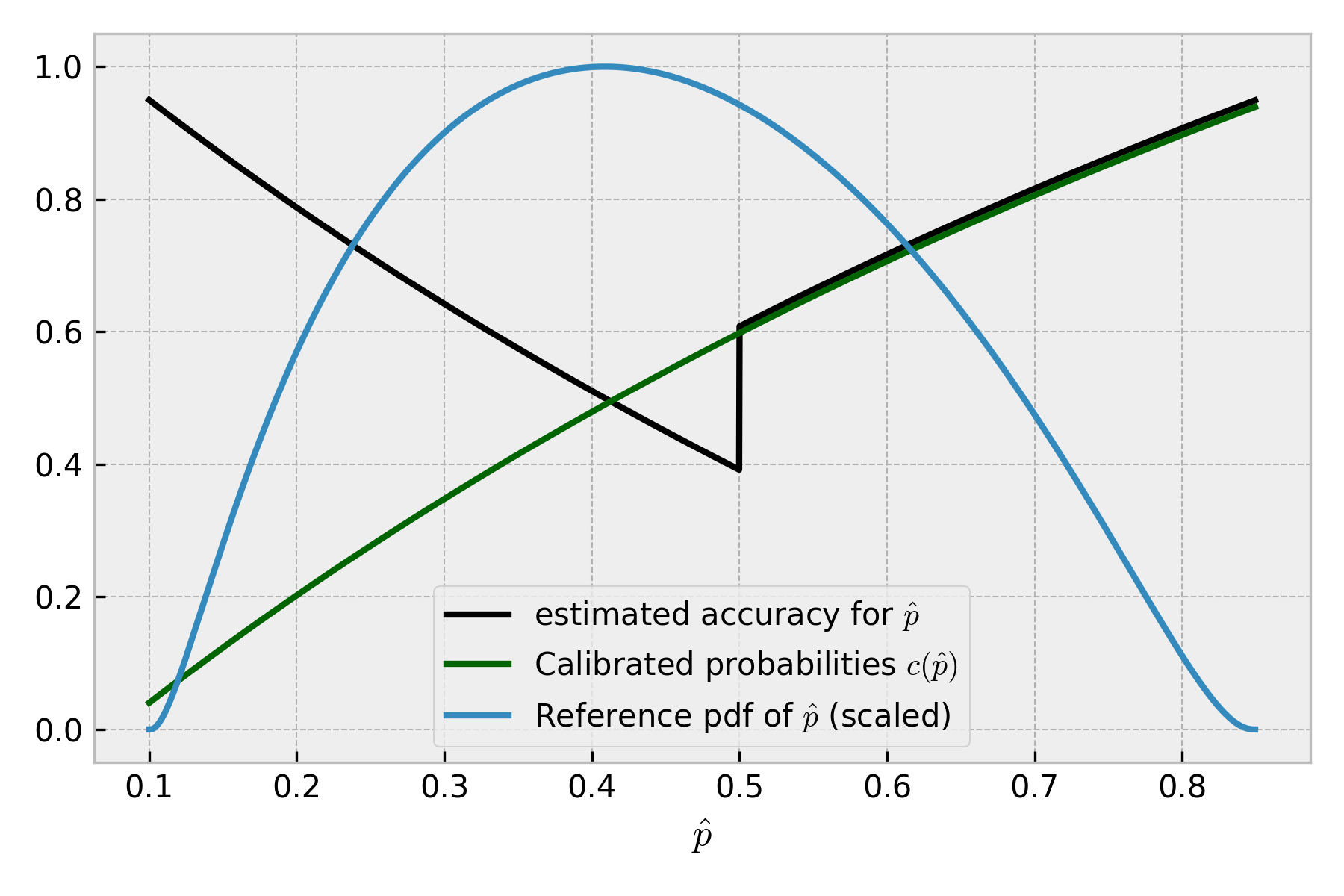
We have a high density of in a low-confidence area (around ) corresponding to a relatively low expected accuracy score, so we don’t expect the accuracy of the model to be high. Multiplying the probability density of by the expected accuracy per value of and taking the integral of that, we get the reference distribution accuracy metric of 0.69. When working on samples of data, not on distributions, we can just calculate the mean of per-observation expected accuracy for the whole sample. That will automatically take the density of into account because if a specific value of is more common, we will simply have more of it in the data, and it will impact the mean stronger. It will give us roughly the same result with precision depending on the amount of available data (as always).
Obviously, no one is interested in estimating performance for the reference data - we have labels there, we can just calculate it. Let’s do it for the shifted data, then. With the pure-covariate-shift assumption, per-observation expected accuracy for a specific value of does not change**! It depends only on the calibrated probabilities and model binary predictions - and these do not change under covariate shift**. What changes is the distribution of different values of . Of course, I’m gonna plot it.
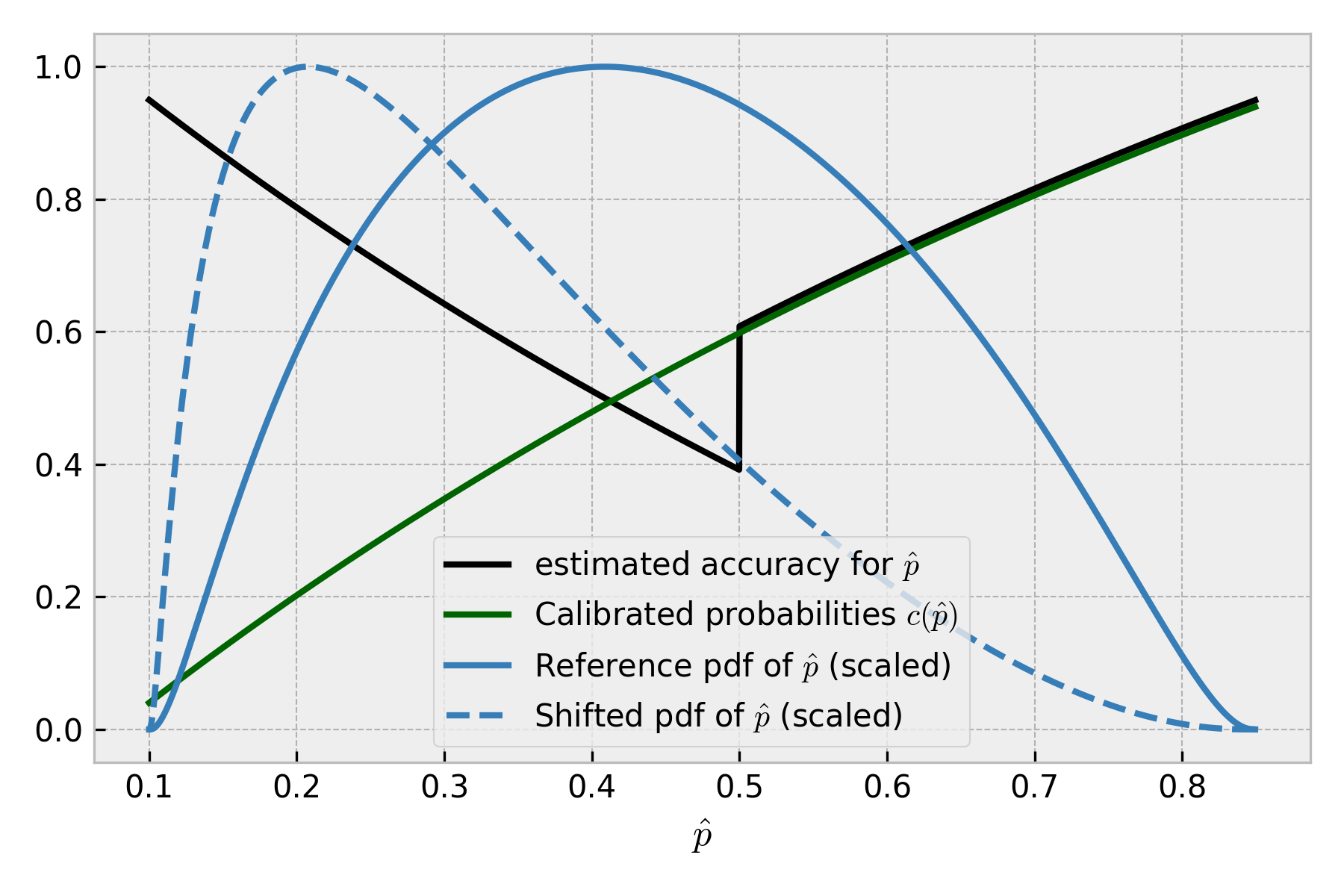
As an effect of covariate shift, the distribution of predicted probabilities shifted towards high-confidence regions ( closer to zero) that correspond to higher expected accuracy scores. Indeed, calculating the integral or the mean again, we get the accuracy estimate after the shift to be equal to 0.76. Notice what we needed to get that number: predictions of uncalibrated model , calibrated probabilities and function that translates these two into performance metric of interest (). The rest was just calculating the mean — no labels used here.
A controversial claim: when the calibration is perfect, estimated performance metric is more accurate indicator of population-level performance than a metric calculated using labels. Take an example: we have 10 observations, all of them with positive binary prediction and calibrated probability of 0.6. Estimated accuracy will be 0.6. Calculated, realized accuracy will be.. well, from 0 to 1. It is not very unlikely that all the labels end up being positive (or negative). Realized accuracy is affected by the uncertainty of probabilities realizing into binary labels, aka sampling error. Estimated accuracy is not. There is one catch though - you cannot fit calibrator on the same sample of data which performance you want to estimate. If you do, the probabilistic performance will be practically the same as the realized performance using labels. In order for this to work, we need to have a big enough reference data set to calibrate on and we have to be sure that calibration holds between reference and monitored data.
*Aaron Roth provided the equation for calibrated classifier, that is when , we have modified it to work with uncalibrated classifier.
** That is simplification which is relevant for the analyzed case. We will see that it does not have to be true.
Adapting calibration to distribution shift: PAPE
There is a chance, that a covariate shift will happen in a way that makes the trained calibrator no longer accurate on shifted data. The stronger the drift is, the more impact this effect will have on the quality of performance estimation. To showcase that, we will slightly complicate our example. Now consider one more input in our model: applicant’s sex. It is a categorical variable that takes two values: female or male. So now we have with being income level and - sex. Assume that in the reference situation there’s 50/50 split between female and male credit applicants. Let’s take our favorite, by default calibrated probability of 0.2. Some subset of observations get this predicted probability of 0.2. Half of the applicants in this subset are women, and the other half are men. When taken together, the positive target fraction is around 0.2 (so the predicted probability is calibrated). However, when calculated for each group independently, that fraction is 0.04 for women and 0.36 for men. Plotting it:
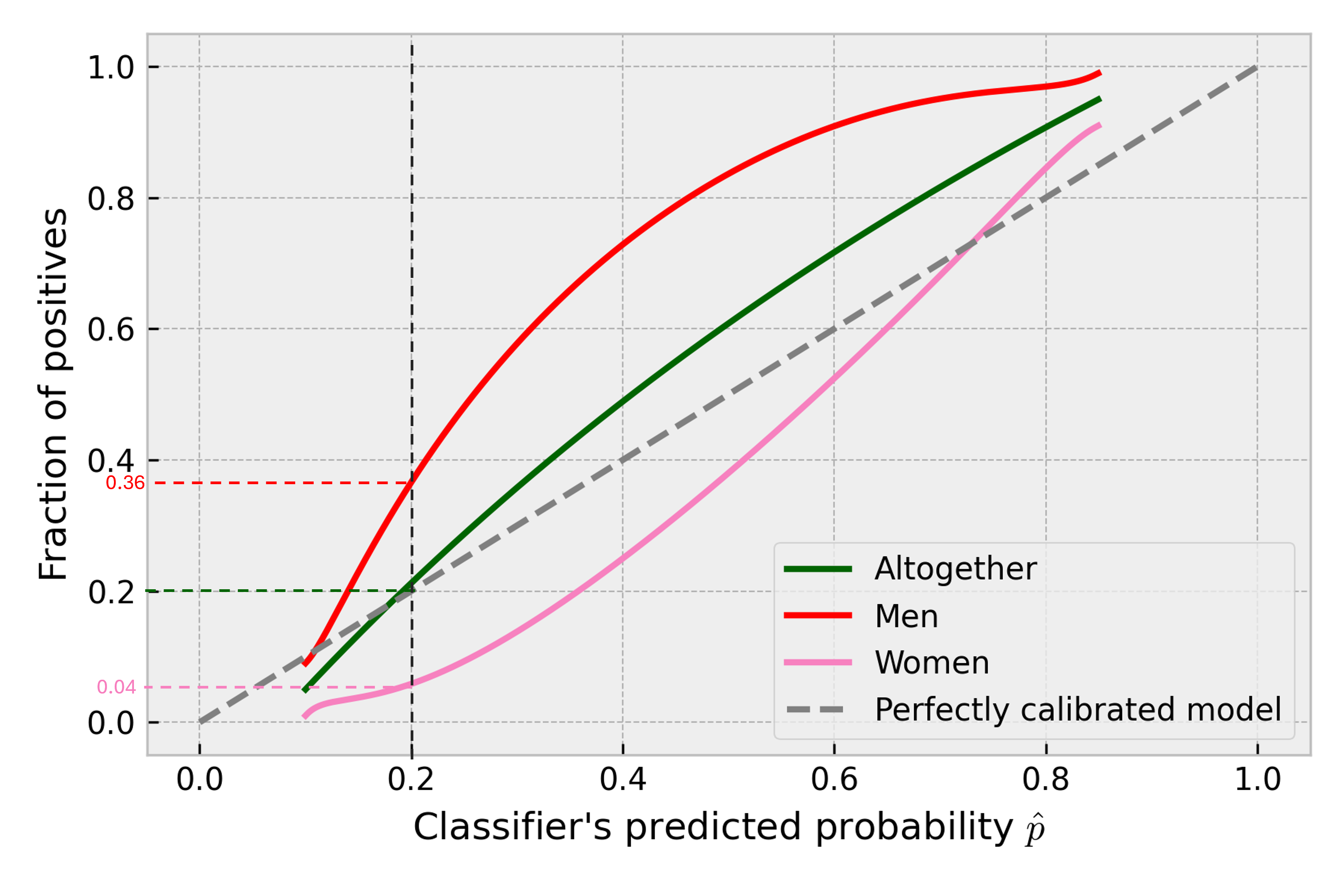
Now consider a strong covariate shift along the dimension of that categorical feature. For example, in the newly shifted data, only female applicants are present. Then, the calibrator will not return calibrated scores for that data anymore. Sticking to the example, it will give , but the fraction of positives for female applicants with this is 0.04. The more extreme the shift is with respect to that variable, the worse the calibration → less accurate performance estimation of CBPE.
How to fix this? The first solution that comes to mind is to just train a calibrator conditioned on inputs. It would work… in our example. But it is much harder in reality. It is difficult to estimate the probability of observing positive targets by just calculating a fraction of positive targets conditioned on specific values of inputs. It requires having multiple observations with exactly the same inputs. Usually, we observe only one record for a specific vector of inputs. And one label - 0 or 1. So calculating fraction of positives directly becomes impossible. To make it feasible, we can try to combine similar inputs into groups and condition on those groups etc. But how do you know which groups are relevant? In real life scenarios we have multiple features, how to decide along which of these we should group? It is like trying to predict the future covariate shift. There is a better way. Instead, we can calibrate the model conditioned on predicted probabilities just like we did last time, but adapt the calibration process to the distribution of shifted input data. This is what Probabilistic Adaptive Performance Estimation does.
The approach of making some property or statistic correct under a new distribution by recalculating it using information about that distribution shift is called Importance Weighting (IW). It’s been around for a while, and it is being rediscovered from time to time. In IW, the distribution shift is described by the probability density ratio: . Simplifying a bit, it tells how much more likely it is to observe a specific input after the shift compared to the reference distribution. Now, if we fit a calibrator with reference data but weighted by those density ratios, it will provide calibrator probabilities after the shift. Let’s work out the intuition with the 0.2 predicted probability and assume covariate shift only along the sex dimension (income distribution remains the same). So for each reference observation, we calculate the density ratio that describes the shift. After the shift, all the applicants are women so . In the reference data, half of the applicants are men, so . The weights for observations with female applicants are then equal 2. Doing the same math for men, their weights become 0 (no male applicants are in the shifted data). Now, fitting a weighted calibrator (regressor) with those weights on reference data will only account for women, as men get zero weights. So the weighted calibrator will now return calibrated score of 0.04 for the raw model predicted probability of 0.2, that is . Showing the effect of calibration in the plot:
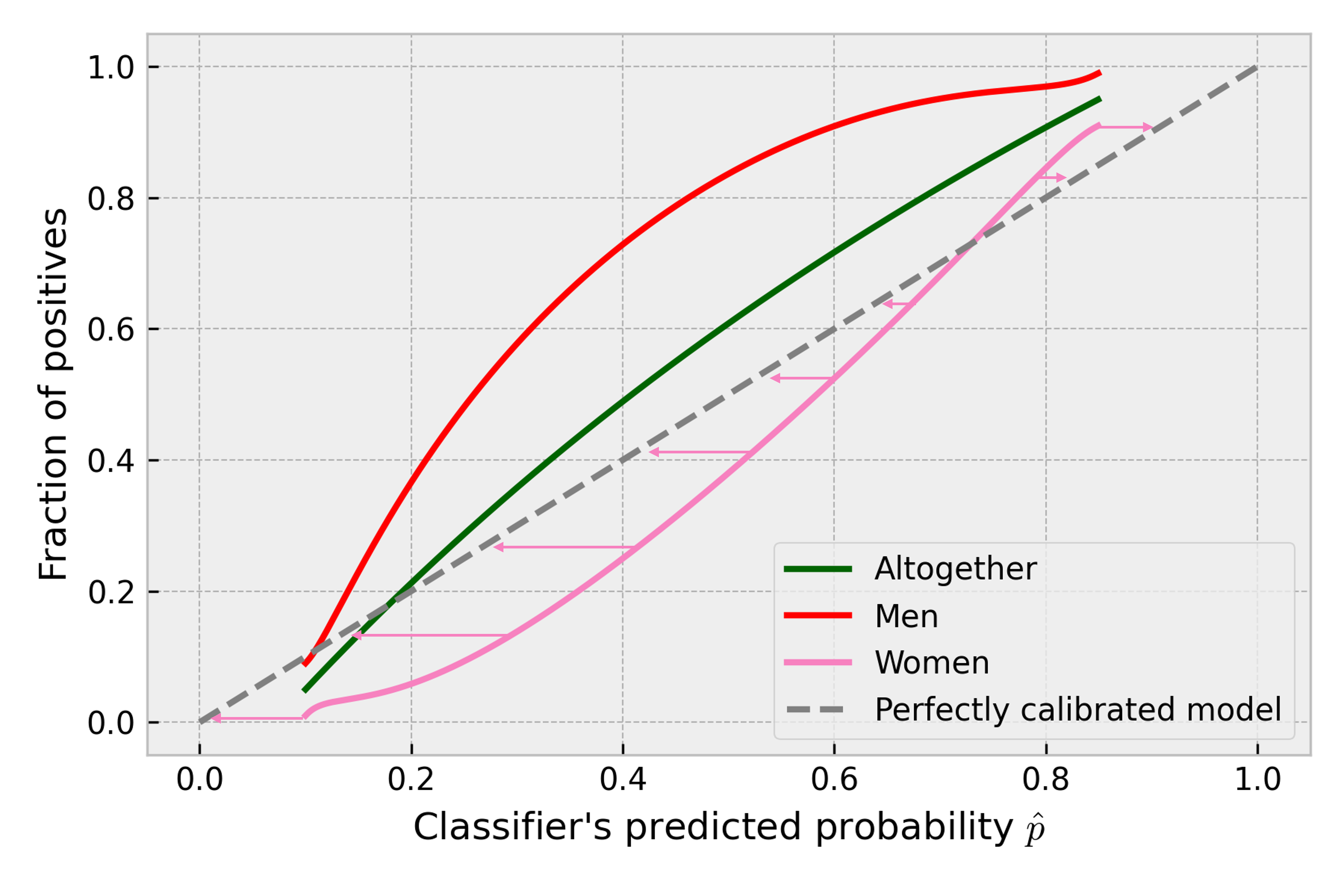
If the shift is less extreme, the weights will be more balanced between men and women. If nothing changes, all the weights are equal to 1, and the calibrator is the same as the calibrator in CBPE. The weights can have a great impact on the calibrator - see how the predicted probability is updated with calibrator depending on the distribution in the shifted data:
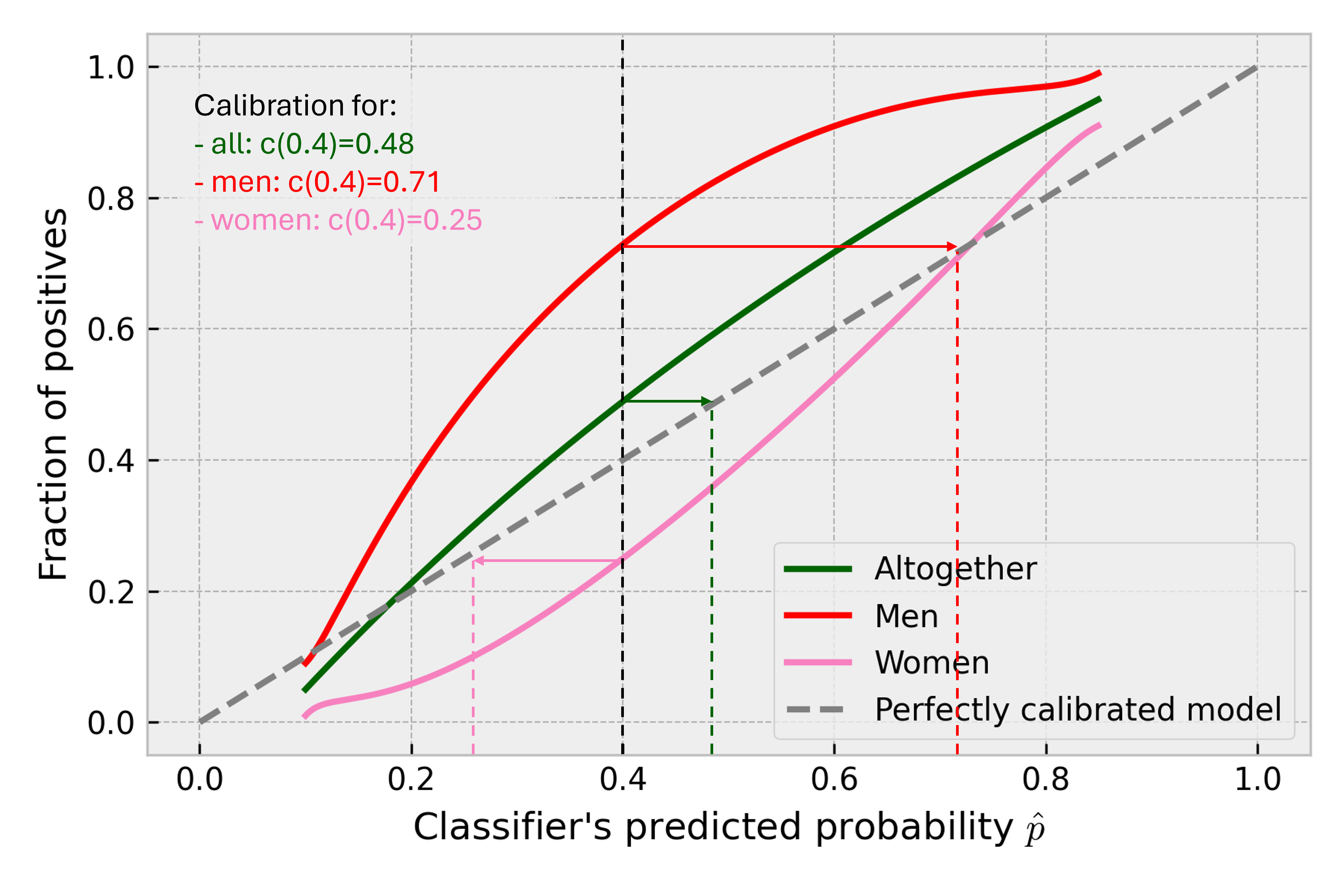
In reality we have to take into account all the dimensions, so these shift density ratios have to be calculated for each point considering all the inputs. This task is well known to the research community, and it is called density ratio estimation. Some approaches try to estimate the densities for the reference and shifted data (within that research area called source and target data) separately and then calculate the ratio. Just like we did in the naive example above. It has been proven, though, that this is more difficult than estimating the ratio directly [1]. Which is what we do in PAPE. We train a classifier that tries to distinguish between reference and shifted data. The reference data observations are labeled 0, and the shifted data observations are labeled 1. We train that DRE (density-ratio-estimation) classifier on combined reference and shifted data, all the inputs of the monitored model, and the labels I just introduced. Then, we use it to get probability estimates on reference data. And then calculate the weights. The probability estimate of the DRE classifier indicates the probability of an observation being representative of the shifted data distribution. Denoting predicted probability returned by DRE as we get the weights by:
The is a positive number close to zero, and it is there only to ensure we never divide by zero when . So, for example, when we get a DRE probability estimate of 0.5, then the weight is approximately 1. If there’s no covariate shift, all the estimates will be close to 0.5 as DRE classifier is not able to distinguish the reference and shifted data. The weights are all close to 1, and the calibration process is similar to unweighted calibration. Now, if there’s a strong covariate shift, DRE is able to indicate reference observations that look more like shifted data and will assign them a higher probability estimate. They will then get more important information in the calibration process, which is what we want.
Now, let’s introduce 3rd example of data shift - both input variables shift at the same time. So there’s extreme shift to female-only applicants, and a moderate income shift (as before). Here’s a table with all 3 shifts, true accuracy (using oracle knowledge about the labels in the shifted data) and estimated accuracy (with no oracle knowledge on shifted labels, but with oracle knowledge on input distributions):
covariate shift description | CBPE accuracy estimate | PAPE accuracy estimate | True accuracy score (Oracle) |
change in income distribution (Figure 3) | 0.76 | 0.76 | 0.76 |
change in applicant’s sex distribution, from equal split to female only | 0.69 (same as on reference data) | 0.74 | 0.74 |
both input variables change | 0.76 | 0.87 | 0.87 |
Let’s check if it makes sense qualitatively for the last type of shift (both variables change). This is what happened:
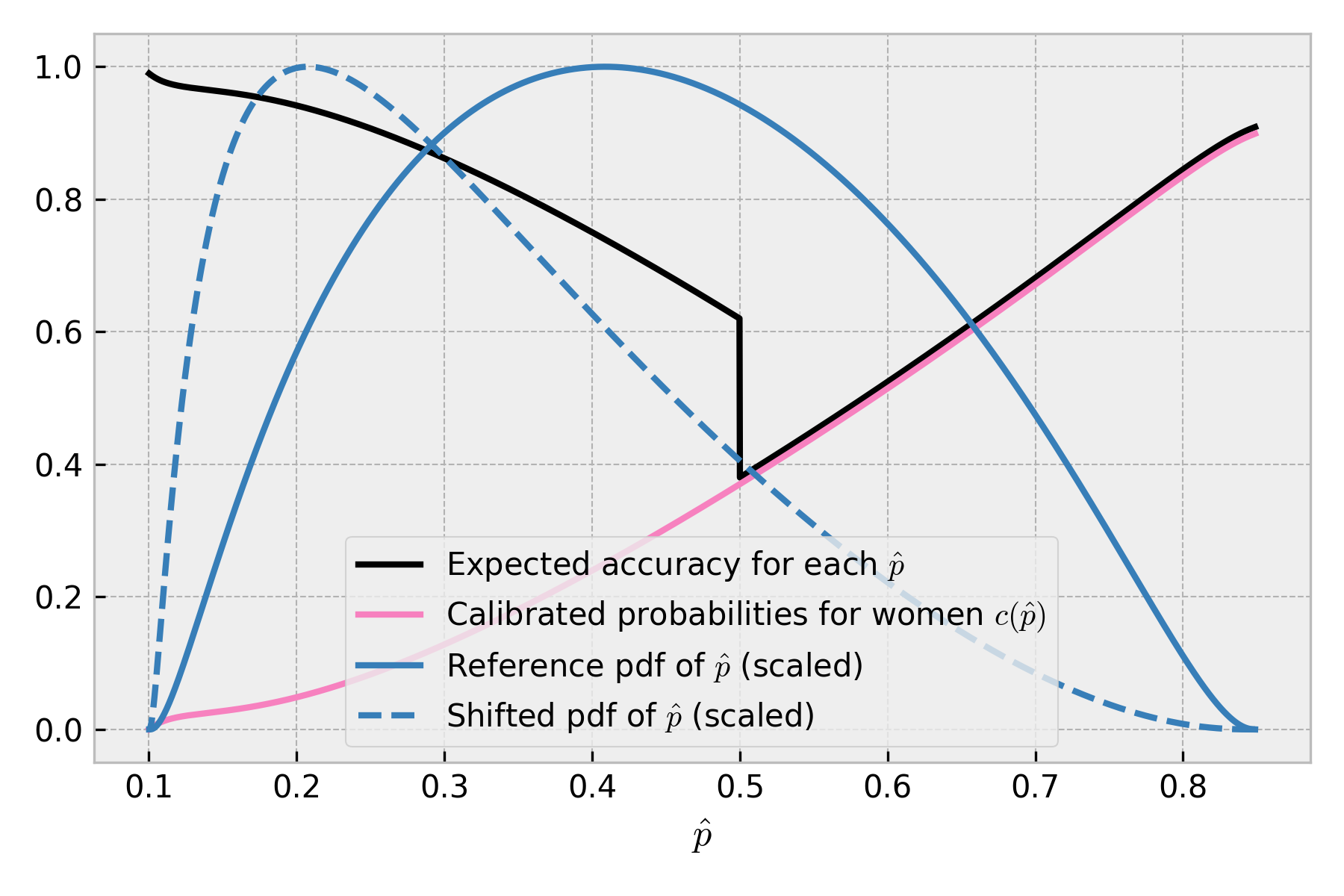
Just as previously, data shifted towards higher-confidence regions ( closer to 0). Still, the model was even more accurate in these regions - the true probability of observing a positive target for low is closer to 0 for female applicants than the balanced group, so the expected accuracy is higher.
Importance-Weighted metric
Alright, if any statistic can be adapted to a distribution shift using an importance weighting procedure, why we just don’t weight the metric itself? The probability (through confidence) can be directly translated into accuracy, even for a single observation. We just showed that. So, the procedure would be to get weights with DRE for each reference observation and calculate weighted performance metrics on the reference data using labels. The observations that look more like the shifted data get a higher weight, so they impact the metric more strongly. It makes sense. Why bother with using probabilities and all the calibration, then?
In fact, on a distribution level (or for a really big data), importance-weighted metric is equivalent to PAPE (which basically is: importance-weighted calibration + translating probabilities into performance metric). However, for smaller samples of the data, closer to real-life scenarios, PAPE is better (Figure 12, [2]). The difference is very subtle and difficult to explain, but we will give it a try.
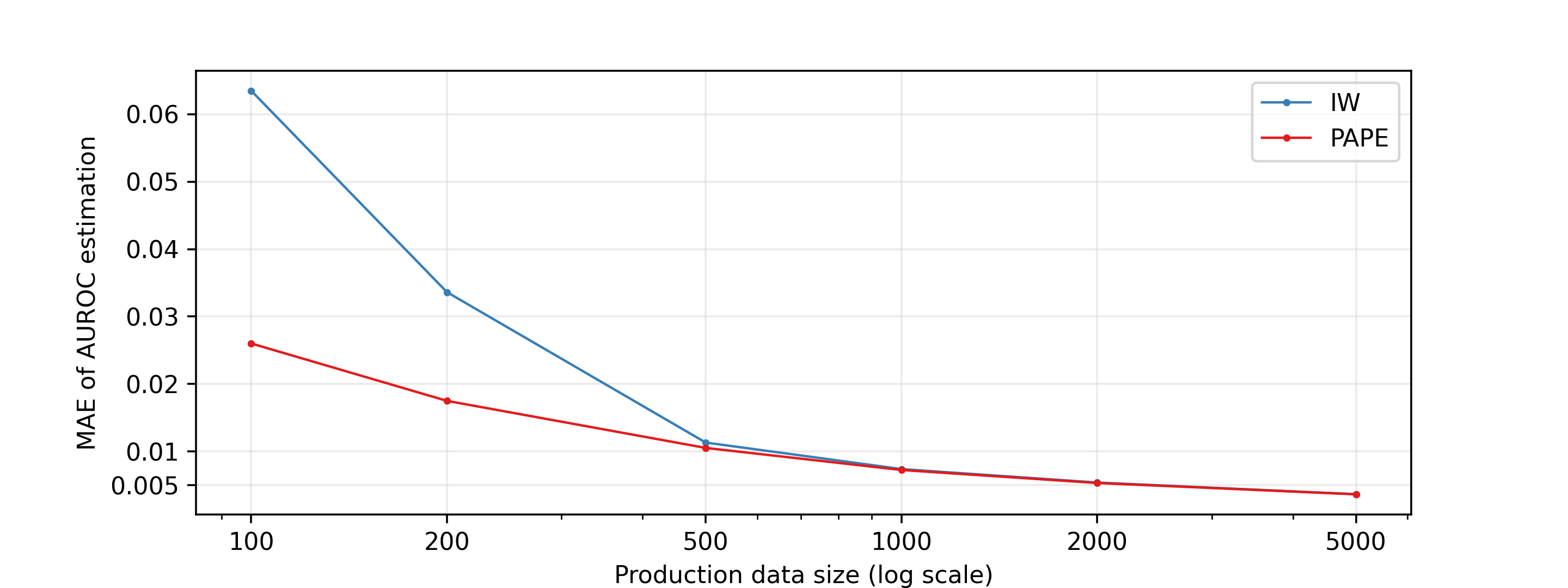
We will focus on the size of the monitored data (that is: the sample of data for which we want to estimate performance of the model, typically post-deployment/production data). First, let’s introduce a two-step model of uncertainty propagation. In the analyzed case, we can think about the random process that takes us to the target value in the following way:
- Randomly sampling from inputs (credit applicant arriving).
- Conditioned on the input sampled, randomly sampling from targets (waiting and checking if the applicant will default).
Say we have a population of inputs (applicants), and the first step of the process is sampling from that population. Each observation (vector of inputs) ingested by our model to be processed into predictions is randomly sampled from that population, which is described by a probability distribution. Let’s get back to the easier, single-input credit default model example. For the shifted data distribution shown in Figure 3 we have a normal distribution of applicant’s income with the mean of 100 kEUR. If we sample tens of thousands of observations, their histogram will pretty accurately follow that distribution. But if we sample 10 observations, we might as well get only applicants with very high income. The high-income applicants will have very low probability of defaulting. We have predicted negative label for these applicants and we expect very high accuracy of these predictions. So we already see that sampling from inputs affects the performance metric we expect to observe. In the described case, we expect to see high accuracy because we happen to observe only high-income applicants that have a close-to-zero probability of defaulting. Then, there is the next step: sampling from the target domain, given the probability of observing a specific target. And even though the probability of default is very low for the high-income applicants, the sampled targets may still end up positive! In such a case, some of the predictions will not be correct, and the accuracy will be lower than expected. That is the second random process that affects the realized performance value calculated for that sample - sampling from targets.
With PAPE, the performance estimate is fully affected by the first source of uncertainty (sampling from inputs). That is because PAPE works on predictions and probability estimates generated by the monitored model based on inputs from the monitored data. It then calibrates these probability estimates (with the weighted procedure). So PAPE comes into play after the first step and takes advantage of its outcomes – inputs are sampled, predictions based on those inputs are generated, and they are used. The only uncertainty left is the one related to calibrated probabilities turning into binary targets. The Importance-Weighted metric (IW) approach is substantially different. The only information that it takes from the monitored data is how its input distribution is related to the reference input distribution (by DRE). So, it looks for similar observations in the reference data and calculates the performance metric by assigning higher weights to those similar observations. It does not take monitored model predictions and probability estimates from the shifted data into account at all. As an effect, it covers only partially the first source of uncertainty. Using the example introduced – when we happen to observe 10 high-income applicants in the monitored data, IW will find similar applicants in reference data and calculate accuracy for these. They will be similar, but – in most cases – they will not be exactly the same. On the other hand, PAPE will estimate the performance metric for exactly those 10 applicants observed in production, using probabilities calibrated on similar applicants from reference data.
What about CBPE? Well, it depends. As I already wrote, if the calibration remains accurate after the shift (as in the first example), CBPE is equivalent to PAPE, so on average, it provides more accurate estimates than IW. When the calibration gets worse due to the shift (as in the second and third example), then IW vs. CBPE battle outcome depends on the balance between the sources of their problems: small sample vs calibration-breaking shift. The smaller the sample size – the worse IW becomes. The more severe the shift and its effect on the calibration accuracy, the worse CBPE is. Measuring and quantifying those effects and their impact is not a trivial thing, though.
The size of the shifted data is one thing, and the size of the reference data is another. Here, differences are also subtle. Take an extreme example first - no reference data at all. All we have is a model that returns some probability estimates. Calibrated or not - we don’t know; there is no data to check yet. IW of the metric alone is infeasible in that case cause there is no data to calculate the weighted performance metric on. We cannot do it on training data – some ML algorithms strongly overfit it, so it will be false by definition. For PAPE, we do not have data for weighted calibration. But we can still use the raw predicted probabilities of the monitored model itself, hoping that its developers made some effort to make it calibrated (or at least not terribly overconfident) and get a reasonable estimation of performance metrics. It will still partially address the covariate shift problem - if there are more predictions from high/low-confidence regions, confidence-based approaches will quantify this effect. Later, as we get more and more data with labels (the reference set is growing), we can improve the calibration. When the reference data set is not empty but still very small, IW gets strongly affected by the random effects. Say that we have only ten observations in the reference data. All of them got a probability estimate of 0.6 and a binary prediction of 1. Just by chance, all of them ended up with positive labels, so the accuracy metric of the reference data is 1. All the weighted accuracies for the incoming, unlabeled monitoring data will be estimated as 1. Depending on how you calibrate, PAPE will take that reference data information into account (by, for example, increasing the probability estimate from 0.6 to 0.7), but it will also smuggle that monitored model knowledge from a training set. It will likely give a less noise-affected estimate.
Summary
CBPE, IW metric, and PAPE are all great performance estimation approaches. With monitored data samples that are not huge, CBPE and PAPE will likely give more accurate estimates, with PAPE being more accurate for stronger shifts. The problem is that we don’t know how strong the shift is upfront, so to be safe, PAPE is the way to go. When the data is really big - IW can also be used. Finally, remember that PAPE and IW are more computationally expensive than CBPE, as they train DRE for each sample of the data on which you want to estimate the performance. CBPE is worth considering in such cases as it is fitted only once – on the reference data.
PAPE and CBPE, being probabilistic methods, have one more advantage – they can provide reliable confidence intervals for their estimates (given all their assumptions are met). Since the only source of uncertainty is the calibrated probabilities realizing into targets, the probability distribution of the performance metric can be estimated. In case of accuracy, we can use poisson-binomial distribution for this [3]. But that… is a topic for another blog post. Let me know if you would like to read it 😊
[1] M. Sugiyama, S. Nakajima, H. Kashima, P. Buenau, and M. Kawanabe, ‘Direct importance estimation with model selection and its application to covariate shift adaptation’. Advances in Neural Information Processing Systems, volume 20. Curran Associates, Inc., 2007.
[2] J. Białek, W. Kuberski, N. Perrakis, and A. Bifet, ‘Estimating Model Performance Under Covariate Shift Without Labels’, arXiv [cs.LG]. 2024.
[3] J. Kivimäki, J. Białek, J. K. Nurminen, and W. Kuberski, ‘Confidence-based Estimators for Predictive Performance in Model Monitoring’, arXiv [cs.LG]. 2024.
Written by
