
A recent study from MIT, Harvard, The University of Monterrey, and other top institutions showed an experiment where 91% of their ML models degrade over time. This study is one of the first of its kind, where researchers focus on studying machine learning models' behavior after deployment and how their performance evolves with unseen data.
“While much research has been done on various types and markers of temporal data drifts, there is no comprehensive study of how the models themselves can respond to these drifts.”
Since we at NannyML are on the mission of babysitting ML models to avoid degradation issues, this paper caught our eye. This blog post will review the most critical parts of the research, highlight their results, and stress the importance of these results, especially for the ML industry.
Introduction
If you have been previously exposed to concepts like covariate shift or concept drift, you may be aware that changes in the distribution of the production data may affect the model's performance. This phenomenon is one of the challenges of maintaining an ML model in production.
By definition, ML models depend on the data it was trained on, meaning that if the distribution of the production data starts to change, the model may no longer perform as well as before. And as time passes, the model's performance may degrade more and more. The authors like to refer to this phenomenon as "AI aging." At NannyML, we call it model performance deterioration and depending on how significant the drop in performance is, we consider it an ML model failure.
The authors developed a testing framework for identifying temporal model degradation to get a better understanding of this phenomenon. Then, they applied the framework to 32 datasets from four industries, using four standard ML models to investigate how temporal model degradation can develop under minimal drifts in the data.
Models and Data
To avoid any model bias, the authors chose four different standard ML methods (Linear Regression, Random Forest Regressor, XGBoost, and a Multilayer Perceptron Neural Network). Each of these methods represents different mathematical approaches to learning from data. By choosing different model types, they were able to investigate similarities and differences in the way diverse models can age on the same data.
Similarly, to avoid domain bias, they chose 32 datasets from four industries (Healthcare, Weather, Airport Traffic, and Financial).
Another critical decision is that they only investigated pairs of model-dataset with good initial performance. This decision is crucial since it is not worthwhile investigating the degradation of a model with a poor initial fit.
.avif)
Proposed Framework
To identify temporal model performance degradation, the authors designed a framework that emulates a typical production ML model. And ran multiple dataset-model experiments following this framework.
For each experiment, they did four things:
- Randomly select one year of historical data as training data
- Select an ML model
- Randomly pick a future datetime point where they will test the model
- Calculate the model’s performance change
To better understand the framework we need a couple of definitions. The most recent point in the training data was defined as \(t_0\). The number of days between $t_0$ and the point in the future where they test the model was defined as \(dT\), which symbolizes the model's age.
For example, a weather forecasting model was trained with data from January 1st to December 31st of 2022. And on February 1st, 2023, we ask it to make a weather forecast.
In this case
- \(t_0\) = December 31st, 2022 since it is the most recent point in the training data.
- \(dT\) = 32 days (days from December 31st and February 1st). This is the age of the model.
The diagram below summarizes how they performed every "history-future" simulation. We have added annotations to make it easier to follow.
-1%202.avif)
To quantify the model’s performance change, they measured the mean squared error (MSE) at time \(t_0\) as \(MSE(t_0)\) and at the time of the model evaluation as \(MSE(t_1)\).
Since \(MSE(t_0)\) is supposed to be low (each model was generalizing well at dates close to training). One can measure the relative performance error as the ratio between \(MSE(t_0)\) and \(MSE(t_1)\).
$E_{rel}(dT) = \dfrac{MSE(t_1)}{MSE(t_0)}$
The researchers ran 20,000 experiments of this type for each dataset-model pair! Where \(t_0\) and \(dT\) were randomly sampled from a uniform distribution.
After running all of these experiments, they reported an aging model chart for each dataset-model pair. This chart contains 20,000 purple points, each representing the relative performance error \(E_{rel}\) obtained at \(dT\) days after training.
.avif)
The chart summarizes how the model's performance changes when the model's age increases.
Key takeaways:
- The error increases over time: the model becomes less and less performant as time passes. This may be happening due to a drift present in any of the model's features or due to concept drift.
- The error variability increases over time: The gap between the best and worst-case scenarios increases as the model ages. When an ML model has high error variability, it means that it sometimes performs well and sometimes badly. The model performance is not just degrading, but it has erratic behavior.
The reasonably low median model error may still create the illusion of accurate model performance while the actual outcomes become less and less certain.
Major Degradation Patterns
After performing all the experiments for all 4 (models) x 32 (datasets) = 128 (model, dataset) pairs, temporal model degradation was observed in 91% of the cases. Here we will look at the four most common degradation patterns and their impact on ML model implementations.
Gradual or no degradation
Although no strong degradation was observed in the two examples below, these results still present a challenge. Looking at the original Patient and Weather datasets, we can see that the patient data has a lot of outliers in the Delay variable. In contrast, the weather data has seasonal shifts in the Temperature variable. But even with these two behaviors in the target variables, both models seem to perform accurately over time.
.avif)
The authors claim that these and similar results demonstrate that data drifts alone cannot be used to explain model failures or trigger model quality checks and retraining.
We have also observed this in practice. Data drift does not necessarily translates into a model performance degradation. That is why in NannyML's ML monitoring workflow, we focus on performance monitoring and use data drift detection tools only to investigate plausible explanations of the degradation issue since data drifts alone should not be used to trigger model quality checks.
Explosive degradation
Model performance degradation can also escalate very abruptly. Looking at the plot below, we can see that both models were performing well in the first year. But at some point, they started to degrade at an explosive rate. The authors claim that these degradations can't be explained alone by a particular drift in the data.
.avif)
Let's compare two model aging plots made from the same dataset but with different ML models. On the left, we see an explosive degradation pattern, while on the right, almost no degradation was seen. Both models were performing well initially, but the neural network seemed to degrade in performance faster than the linear regression (labeled as RV model).
.avif)
Given this, and similar results, the authors concluded that Temporal model quality depends on the choice of the ML model and its stability on a certain data set.
In practice, we can deal with this type of phenomenon by continuously monitoring the estimated model performance. This allows us to address the performance issues before an explosive degradation is found.
Increase in error variability
While the yellow (25th percentile) and the black (median) lines remain at relatively low error levels, the gap between them and the red line (75th percentile) increases significantly with time. As mentioned before, this may create the illusion of an accurate model performance while the real model outcomes become less and less certain.
.avif)
Neither the data nor the model alone can be used to guarantee consistent predictive quality. Instead, the temporal model quality is determined by the stability of a specific model applied to the specific data at a particular time.
Potential Solutions
Once we have found the underlying cause of the model again problem, we can search for the best technique to fix the problem. The appropriate solution is context-dependent, so there is no simple fix that fits every problem.
Every time we see a model performance degradation, we should investigate the issue and understand the cause of it. Automatic fixes are almost impossible to generalize for every situation since the degradation issue can be caused by multiple reasons.
In the paper, the authors proposed a potential solution to the temporal degradation problem. It is focused on ML model retraining and assumes that we have access to newly labeled data, that there are no data quality issues, and that there is no concept drift. To make this solution practically feasible, they mentioned that one needs the following:
1. Alert when your model must be retrained.
Alerting when the model's performance has been degrading is not a trivial task. One needs access to the latest ground truth or be able to estimate the model's performance. Solutions like NannyML can help to do that. For example, NannyML uses probabilistic methods to estimate the model's performance even when targets are absent. They monitor the estimated performance and alert when the model has degraded.
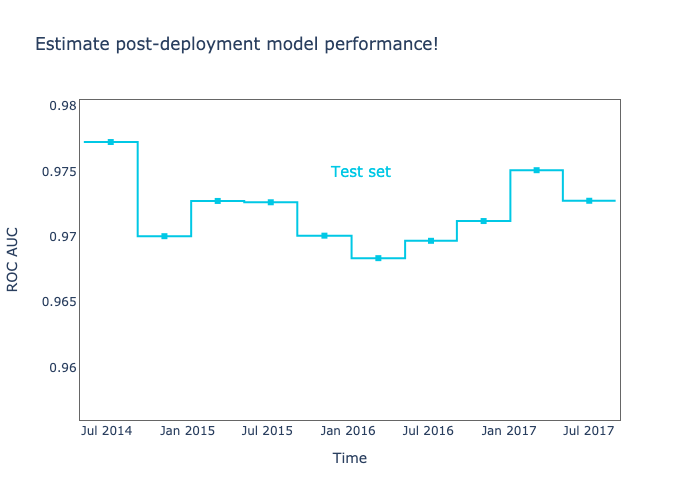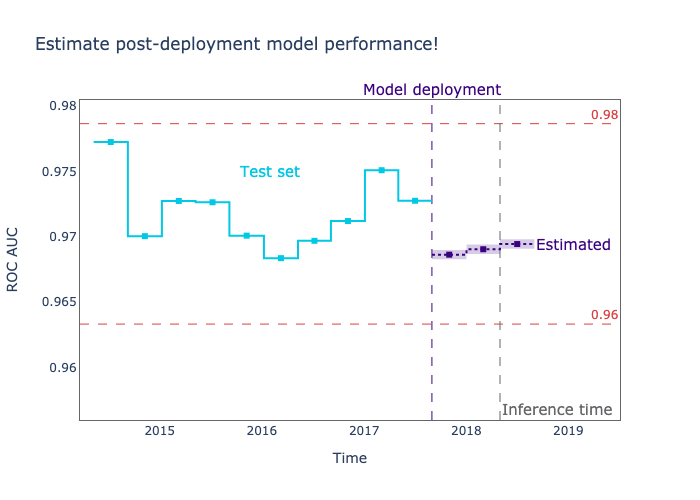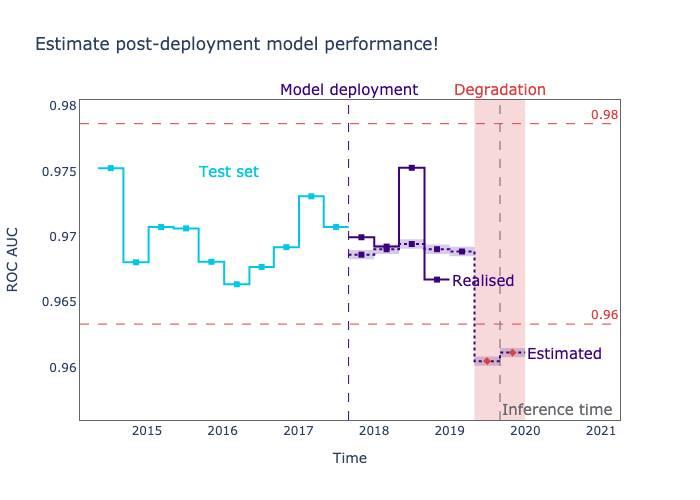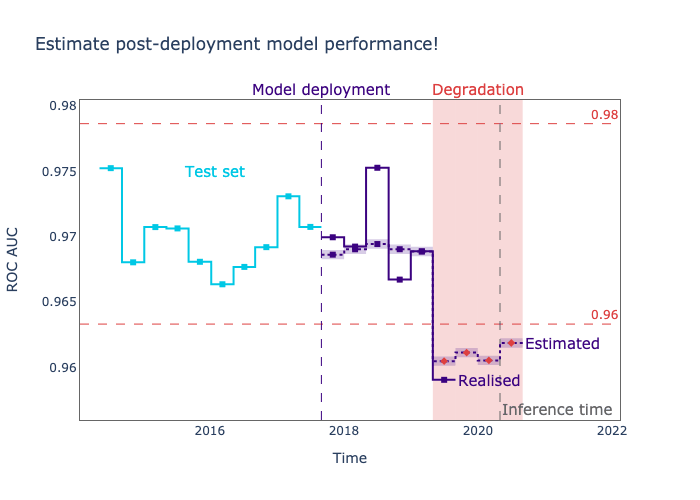
2. Develop an efficient and robust mechanism for automatic model retraining.
If we know that there is no data quality issue or concept drift, frequently retraining the ML model with the latest labeled data could help. However, this may cause new challenges, such as lack of model convergence, suboptimal changes to the training parameters, and "catastrophic forgetting" which is the tendency of an artificial neural network to abruptly forget previously learned information upon learning new information.
3. Have constant access to the most recent ground truth.
The most recent ground truth will allow us to retrain the ML model and calculate the realized performance. The problem is that in practice, ground truth is often delayed, or it is expensive and time-consuming to get newly labeled data.
When retraining is very expensive, one potential solution would be to have a model catalog and then use the estimated performance to select the model with the best-expected performance. This could fix the issue of different models aging differently on the same dataset.
Other popular solutions used in the industry are reverting your model back to a previous checkpoint, fixing the issue downstream, or changing the business process. To learn more about when it is best to apply each solution check out our previous blog post on How to address data distribution shift.
Conclusions
The study by Vela et al. showed that the ML model's performance doesn't remain static, even when they achieve high accuracy at the time of deployment. And that different ML models age at different rates even when trained on the same datasets. Another relevant remark is that not all temporal drifts will cause performance degradation. Therefore, the choice of the model and its stability also becomes one of the most critical factors in dealing with performance temporal degradation.
These results give a theoretical backup of why tools like NannyML are important for the ML industry. Furthermore, it shows that ML model performance is prone to degradation. This is why every production ML model must be monitored. Otherwise, the model may fail without alerting the businesses.
If you want to know more about how to monitor your ML models, check out Monitoring Workflow for Machine Learning Systems.
References
- Vela, D., Sharp, A., Zhang, R., et al. Temporal quality degradation in AI models. Sci Rep 12, 11654 (2022). https://doi.org/10.1038/s41598-022-15245-z
NannyML is fully open-source, so don’t forget to support us with a ⭐ on Github! If you want to learn more about how to use NannyML in production, check out our other docs and blogs!







