
Do not index
Canonical URL
Introduction
You've worked tirelessly to implement a predictive maintenance model for the production lines at a manufacturing company. The model works well during testing, and you confidently deploy it. It's been sailing smoothly for a few months.
One afternoon, your manager calls: "We've just had a major equipment failure. The production line is down, and we'll lose clients. Wasn't the predictive maintenance model supposed to catch this?"
The model failed silently, and now you're left scrambling to explain why. The equipment breakdown is never just a technical failure—it’s now a financial disaster and a major setback for the company. Your team had relied on the model to catch such issues and now the repercussions are severe.
When models fail silently, they lead to substantial financial losses, safety risks, and a significant loss of trust in data-driven solutions.
In this blog, we will focus on the challenges of monitoring predictive maintenance models and how you, as a data scientist, can set up a robust model monitoring workflow to detect failures early.
The Problem of Missing Targets and The Censored Confusion Matrix
Predictive maintenance models (PdM) are machine learning models developed on historical data to predict possible machine failures. These predictions are then used to create a dynamic maintenance schedule to improve the machine's lifespan and operational efficiency.
Like all machine learning models, PdMs fail silently if not monitored properly. They present a unique monitoring challenge. If a model predicts a machine breakdown and maintenance is scheduled, the machine might never fail in real life.
This raises the question: How can we be sure the model was correct? Is there a way to know whether or not our machine would have failed if we had not maintained it?
This lack of failure is our original goal, and it is beneficial. However, it also results in no immediate failure or target data to validate the model’s prediction. The critical feedback is delayed, and the resultant confusion matrix is “censored”.
.png)
The target data is often delayed due to the nature of maintenance events and how they are recorded in real-world scenarios. For example, technicians may take time after a maintenance event to document the issue, update logs, and input this information into the system, postponing the availability of the actual target data. Decisions based on model predictions can lead to over-maintenance or unexpected failures. Both scenarios are costly—over-maintenance increases operational costs, while unforeseen failures lead to downtime and potential safety issues.
We need a robust monitoring framework to tackle these challenges and keep our models accurate.
The ML Monitoring Workflow
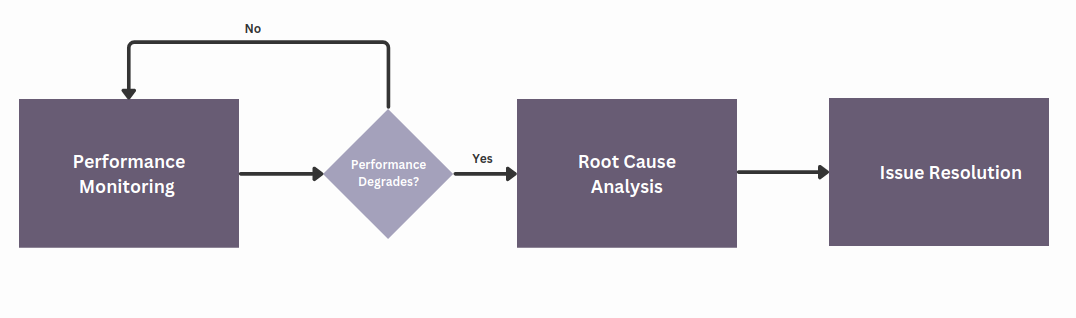
The objective is to set up a system that can nil machine failure cases while increasing the visibility of your work. Our three-phase monitoring workflow is designed so that your models continue to help you achieve and exceed business metrics. The three phases are performance evaluation or estimation, root cause analysis, and issue resolution.
Classification performance metrics like accuracy and precision are all calculated based on the confusion matrix. Since this matrix is censored in PdM models, we must estimate performance. The Confidence-Based Performance Estimation algorithm provided by NannyML estimates these missing metrics in the first phase of our monitoring workflow.
If you would like to apply this workflow directly to your models, check out this hands-on guide with NannyML Cloud.

.jpg?table=block&id=3eb03532-5e9b-4fe2-a354-9d4918cc1ec1&cache=v2)
Confidence-Based Performance Estimation
One way to solve the “censored” confusing matrix problem is to use performance estimation algorithms like Confidence-Based Performance Estimation(CBPE).
The core intuition of this method is that the predicted probabilities from a classification model can estimate the errors and thus reflect on the model’s accuracy.
Here’s how CBPE achieves this:
- The first step involves collecting the outputs from the classification model, which includes the predicted class labels and the associated probabilities.
- Calibrate and adjust the predicted probabilities to reflect an event's likelihood better.
- We estimate the elements of the confusion matrix for each round of prediction.
- Get the aggregate confusion matrix per chunk. By estimating the probabilities of correct and incorrect predictions, CBPE “uncensored” the confusion matrix.
- This aggregated confusion matrix for each chunk can be used to compute any of the performance metrics. These metrics provide insights into the model’s performance over time or across different data segments.

To learn more about CBPE in detail, check out our documentation.
Suppose our estimations signal a possible model failure or overall model breakdown. In that case, we can move into the next phases of the workflow, which is root cause analysis and issue resolution.
Root Cause Analysis
Root cause analysis helps us narrow the exact cause of anomalies in machine learning models.
Univariate drift detection focuses on detecting changes in the distribution of an individual feature. It involves comparing newer data distributions to older ones to spot deviations or shifts. These methods include Jensen-Shannon Distance, Hellinger Distance, Kolmogorov-Smirnov Test, Wasserstein Distance, Chi-squared Test and L-Infinity Distance. To choose from the options, consider the nature of your data and the context of your analysis. To learn about these methods in detail, check out this comprehensive guide.
Multivariate drift detection goes one step further by taking into account multiple features. NannyML has developed two key algorithms: Data Reconstruction using PCA, which evaluates structural changes in data distribution, and Domain Classifier Method, which focuses on discriminative performance. Read this blog for a detailed comparison between these two methods using a real-world dataset.
Simple Checks ensure the completeness and relevance of the data. Unseen data detection identifies new data types the model hasn't encountered before. Missing data detection looks for gaps in the data. Think of missing sensor readings that hide signs of machine damage.
Issue Resolution
Once we pinpoint the root cause of degradation, we can make several calls as data scientists to resolve these underlying issues. The following are simple bullet points to keep in mind while figuring out how to move forward.
- Retrain the Model: If a model fails to predict a new type of machine vibration that leads to breakdowns, retraining it with recent data that includes this new vibration pattern will improve its predictive capability.
- Adjust Downstream Processes: Sometimes, the issue lies not within the predictive model but in how its predictions are used in downstream processes. Based closely on the insights from the model, adjust scheduling, inventory management, or other related processes.
- Adjust Prediction Thresholds: With your team, analyze the trade-off between false positives (unnecessary maintenance) and false negatives (missed failures). Adjust the prediction threshold to minimize critical errors without overburdening the maintenance team with alert fatigue.
- Fix Data Issues: We do not need to stress the importance of data quality here. Sensor degradation can result from wear, calibration drift, or environmental factors. Any such damage can result in noisy and inaccurate readings. Even when sensors are replaced or recalibrated, inconsistencies in the data can skew model outputs.
- Do Nothing: In some cases, the identified issue may not impact operations or may be a rare occurrence that doesn’t warrant immediate action. Suppose a minor data anomaly is detected but doesn’t affect the overall model performance or operational efficiency. In that case, it might be more efficient to monitor the situation rather than take immediate action.
Conclusion
This blog discussed the challenges of monitoring predictive maintenance models, focusing on missing targets and the censored confusion matrix. We also understood why such issues make performance evaluation difficult.
We introduced a three-phase ML monitoring workflow, beginning with performance estimation using the CBPE algorithm and understanding how it addresses the censored confusion matrix. Next, we briefly discussed root cause analysis using drift detection methods provided by NannyML. Lastly, we outlined strategies you can return to after discovering an issue that must be resolved.

Struggling with Model Performance Anxiety?
Most of your time shouldn't be spent worrying about how well your models perform. Let NannyML take that burden off your shoulders. With our cloud-based monitoring platform, you can focus more on training and deploying models and less on performance worries.
Schedule a demo with a NannyML founder today!
Read More…
These are some of our popular blogs on more such interesting topics:



.jpg?table=block&id=e52f2237-c377-424c-9e57-ab0dfdea3f7a&cache=v2)
Frequently Asked Questions
What is the main goal of predictive maintenance machine learning models?
The main goal of predictive maintenance is to anticipate and prevent equipment failures before they occur. It aims to detect and address issues proactively before they impact business. This approach minimizes downtime, reduces maintenance costs, and extends the lifespan of machinery. It ensures continuous production and operational efficiency, therefore enhancing overall productivity.
How to improve predictive maintenance models?
To improve predictive maintenance models, implement a three-phase monitoring system. First, conduct performance estimations using advanced methods like CBPE. Then, conduct a root cause analysis to understand why your model might fail. This will detect data drift and model performance issues. Lastly, resolve the issues by retaining the model, improving data quality, or adjusting the downstream processes.
How do you collect data for predictive maintenance?
Collect data for predictive maintenance using sensors and IoT devices installed on machinery. These devices gather real-time data on temperature, vibration, and pressure parameters. Integrate this sensor data with historical maintenance records and operational logs.
Written by
