Table of Contents
- Introduction
- What is Data Drift
- NannyML Options for Data Drift: Univariate vs Multivariate Detection
- Univariate
- Multivariate
- Data Drift Methods in Action!
- Set-Up
- Preparing the Reference and Monitoring Data
- Univariate Data Drift Method
- Multivariate Data Drift Method
- Conclusion
- Enjoyed this article - how about some more NannyML blogs?
.png?table=block&id=1a4d2060-6af8-4749-8ec7-fec175a322ef&cache=v2)
Do not index
Canonical URL
Introduction
So, your model’s performance post-deployment has tanked, even after your meticulous evaluations. And now you are struggling to identify what went wrong. The frustration and desperation are building as you see your model’s performance metrics flailing. What will your customers think? How will your team react? Fear not!
Data drift methods provide key insight into possible data distribution changes that can occur while a model is in production. This makes drift detection methods effective for understanding why the performance of your model has dropped after degradation has occurred.
At NannyML, our algorithms empower data scientists to diagnose, visualize, and correct data drifts before they lead to serious financial problems. This blog post aims to explore the concept of data drift. Additionally, it will demonstrate the ease of use of our univariate and multivariate drift detection methods to give you the confidence to use them in the future!
What is Data Drift
Data drift refers to scenarios when the production data distribution changes from that of the trained data distribution. It could be caused by a multitude of different factors, such as user behavior changes, environmental changes, seasonality, data collection changes, etc. Ultimately, data drift is one of the main causes of silent model failure and, if not corrected promptly, can lead to financial and reputational consequences.
NannyML Options for Data Drift: Univariate vs Multivariate Detection
Univariate
NannyML's univariate data drift approach involves examining each input variable fed into the machine learning (ML) model in isolation. Thereafter, we use aggregate metrics of production data samples (called chunks) to perform a comparison between the reference period (which we use to establish the model’s performance expectations with inputs, outputs, and model performance) and the monitoring period (which is the latest production data up to a desired point in the past after the reference period ends).
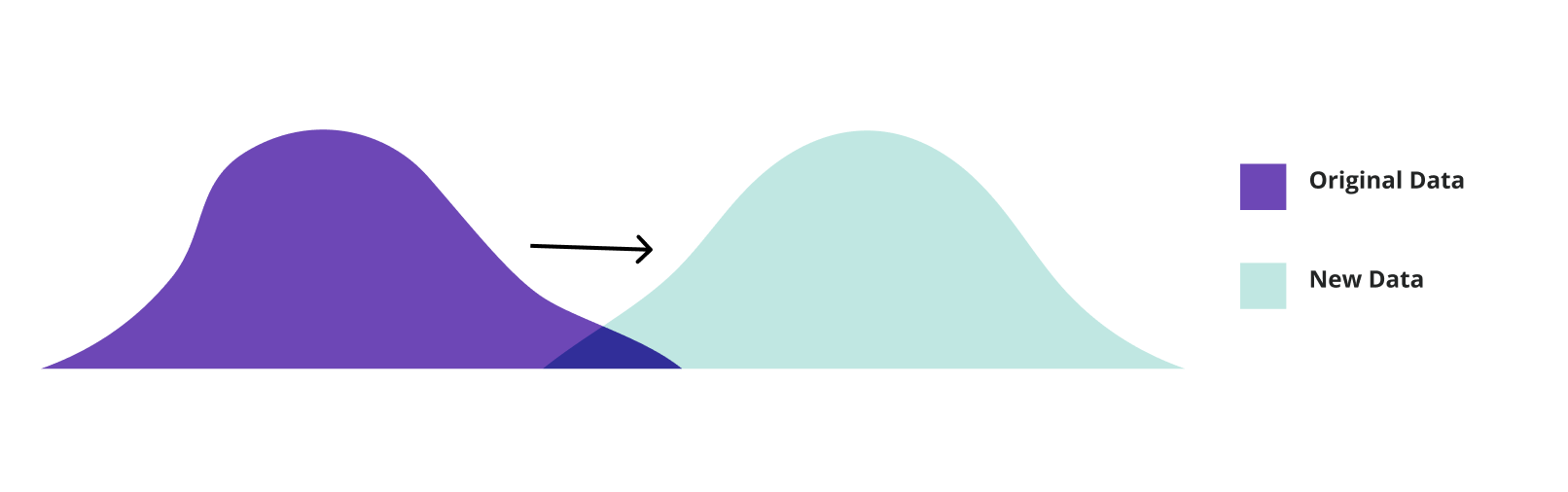
Yet, due to the multidimensional input space of most ML models, univariate data drift methods often fail to detect when joint data distributions change in the absence of individual feature shifts. Univariate methods, therefore, lack the data relationship context between the different input variables for useful overall monitoring as described in Detecting Covariate Shift: A Guide to the Multivariate Approach.
Multivariate
To address univariate data drift methods shortfalls, NannyML offers 2 options: Data Reconstruction with PCA and a Domain Classifier. Both methods require a reference dataset, to assist in providing the model’s performance expectations. The reference dataset is assumed to be stable and meet the required evaluation metrics for its use case. Additionally, a monitoring set is required to determine whether the model performance maintains the expectations set out by the reference dataset.
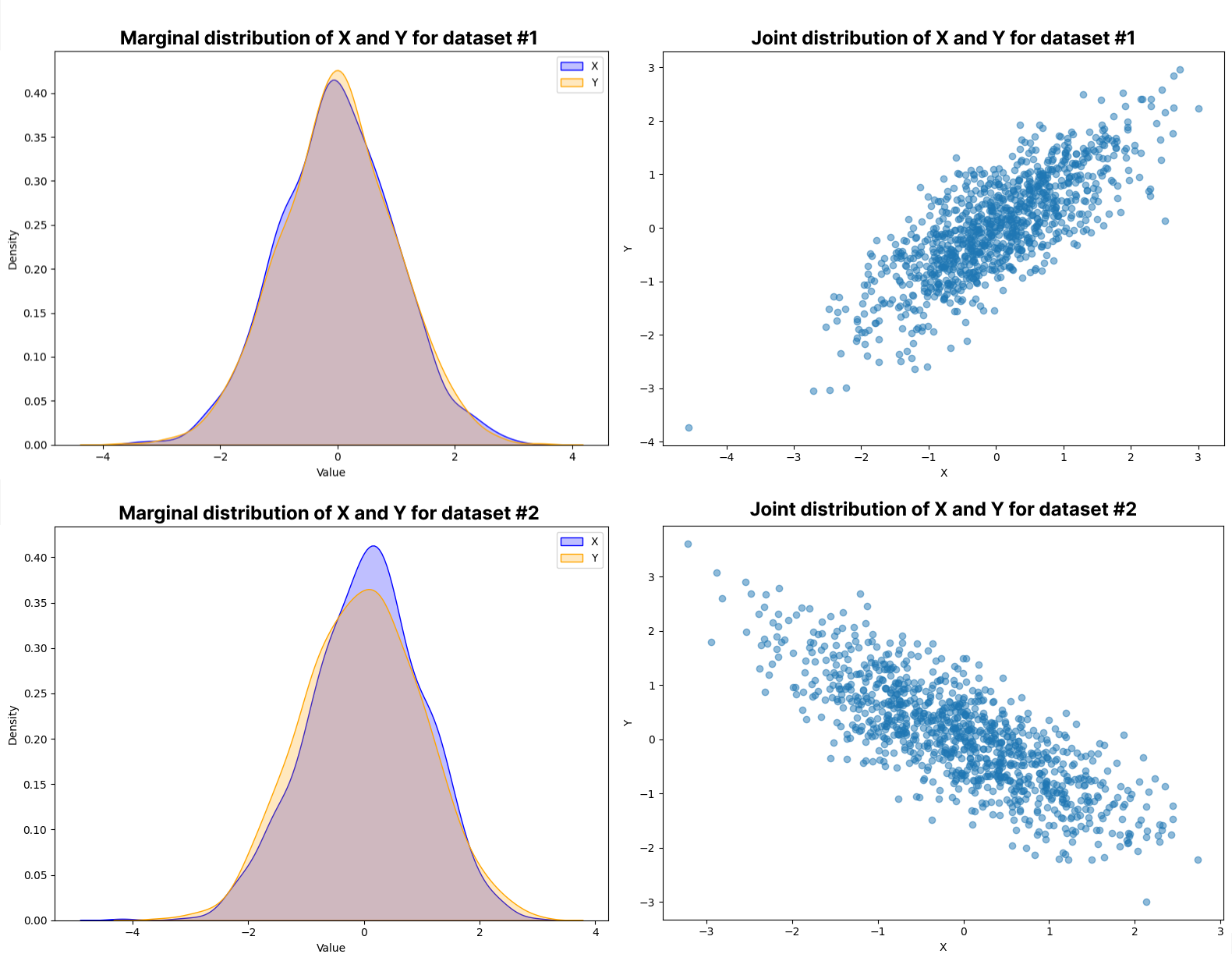
The differences between these two multivariate detection mechanisms are summarized below:
Data Reconstruction with PCA | Domain Classifier |
Multivariate data is converted into its respective uncorrelated principal components. | Multivariate data is used in its original form, and new data points are classified as belonging to either the reference or monitoring period. |
Returns a reconstruction error, which measures the difference between the original and reconstructed PCA components. | Returns a measure of the ease of distinguishing between the reference and monitoring data chunks. |
Significant drift when PCA components cannot reconstruct original data, producing large reconstruction errors. | Significant drift when it is easy to distinguish between the two periods. |
To determine which multivariate data detection method to use - consider the complexity of your data and whether you are prioritizing understanding the underlying data relationships. In these cases of complex data with the desire to understand the underlying relationship, Data Reconstruction with PCA is the better choice. Significant drift, however, will likely be easily displayed in a Domain Classifier without the need to transform the data space.
However, the best method often depends on the specific characteristics of your data and the nature of the drift you are experiencing. It may be useful to experiment with both methods to see which yields the most insightful results for your situation.
Data Drift Methods in Action!
Set-Up
To follow along with this example, download this simple dataset from Kaggle which estimates whether an airline booking is completed based on numerous features such as the number of passengers intending to fly, and the length of the trip.
First, we add an index column to provide a unique identifier for each row’s prediction. This is necessary for the NannyML Cloud platform which uses the index in various processes such as error referencing. For the open-source library implementation, however, this is optional.
Thereafter, we generate synthetic timestamps. The timestamp column enables model monitoring metrics to be referenced to the date they were recorded. This allows subsequent data chunks to have a time-identified x-axis.
import datetime as dt
timestamps = [dt.datetime(2021,1,1) + dt.timedelta(hours=x/2) for x in data.index]Preparing the Reference and Monitoring Data
To set up the data drift analysis, we first need to generate our reference and monitoring chunks. This process begins when setting up your model, whereby the features used are explicitly declared.
features = ['purchase_lead', 'length_of_stay', 'flight_hour', 'flight_day', 'route',
'booking_origin', 'flight_duration']
target = 'booking_complete'
timestamp = 'Timestamp'
train_df, test_df, analysis_df = data.iloc[0:20000], data.iloc[20000:30000], data.iloc[30000:50000]In addition, when portioning your data into training and testing sets, include an analysis set. The test set will go on to be our reference data (since there is no production data yet).
The analysis set is used as the monitoring set via the NannyML libraries. For more information on monitoring and reference dataset requirements, see the Data requirements tutorial.
reference_df = test_df.copy()
monitor_df = analysis_df.copy()Thereafter, we import the NannyML library (see installation assistance for full setup ) and load up the input features as column names.
import nannyml as nml
from IPython.display import display
column_names = featuresFor the set up of the NannyML Cloud service, in addition to the index and timestamp columns, a target prediction and prediction probability are recommended to be included as model outputs. This allows the cloud product to actively engage in estimating model performance. This is easily generated through our produced model,
clf, below.reference_df['y_pred_proba'] = clf.predict_proba(test_df[features])[:, 1]
reference_df['y_pred'] = clf.predict(test_df[features])
reference_df.to_csv('processedReferenceData.csv', index=False)
monitor_df['y_pred_proba'] = clf.predict_proba(monitor_df[features])[:, 1]
monitor_df['y_pred'] = clf.predict(monitor_df[features])
monitor_df.to_csv('processedMonitoringData.csv', index=False)Univariate Data Drift Method
We then set up the univariate drift calculator method with the relevant requisite parameters and plot the results.
calc = nml.UnivariateDriftCalculator(
column_names=column_names,
treat_as_categorical=['y_pred'],
timestamp_column_name='timestamps',
continuous_methods=['jensen_shannon'],
chunk_size=1080 # monitor every 7 days
)
calc.fit(reference_df)
results = calc.calculate(monitor_df)We have the option to visualize either the drift or the distribution for each column. Both will be demonstrated in this example using the Jensen Shannon Distance method. For a full overview of all univariate methods see the Presenting Univariate Drift Detection Methods documentation.
figure = results.filter(column_names=results.continuous_column_names, methods=['jensen_shannon']).plot(kind='drift')
figure.show()
figure = results.filter(column_names=results.continuous_column_names, methods=['jensen_shannon']).plot(kind='distribution')
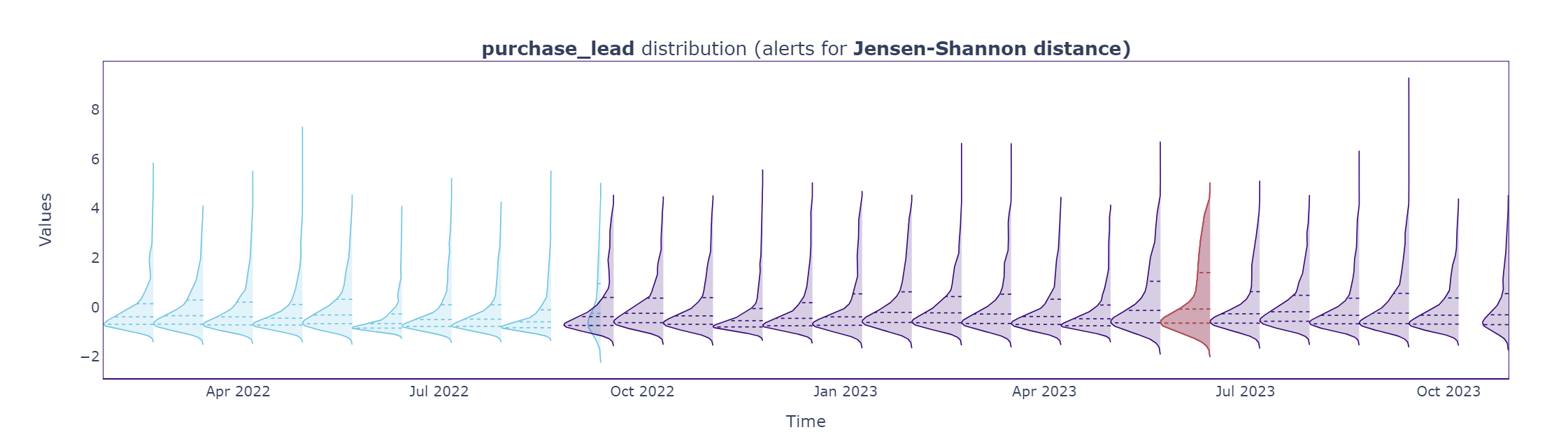
figure.show()Taking the purchase lead variable as an example, we can see the drift metrics graph below. The red diamond for the monitoring period in July 2023 indicates an alert, whereby the set threshold’s value is exceeded and would need to be investigated. The default threshold is set at 3 standard deviations outside of the reference data’s mean. (To set your threshold limits see this tutorial.)
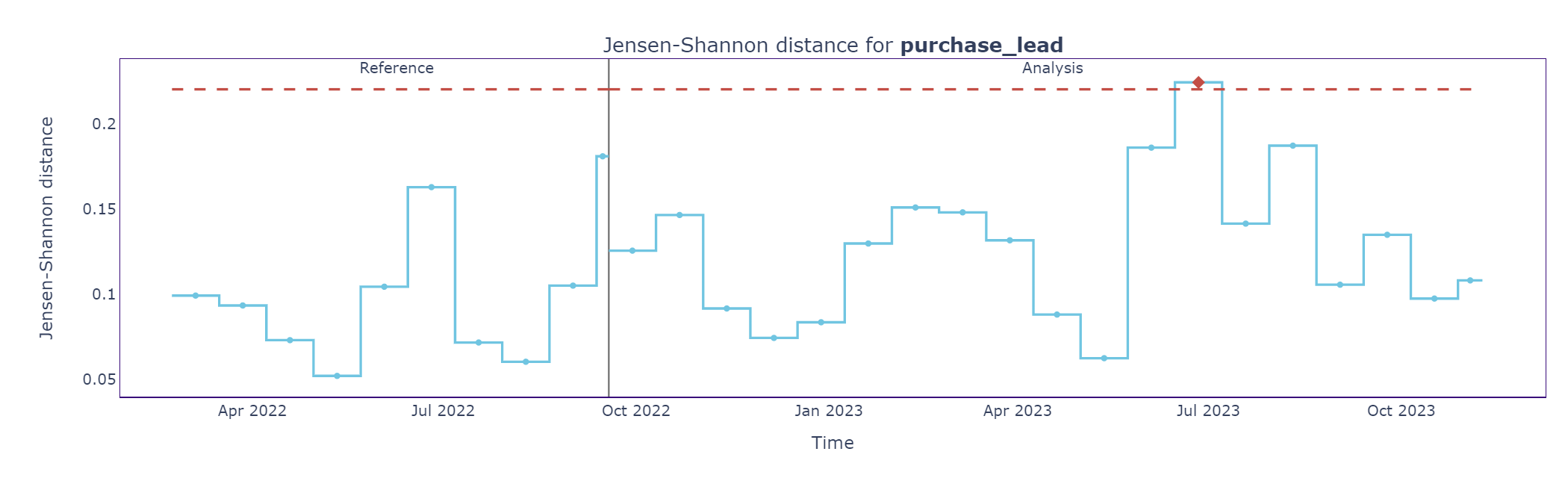
Next, the distribution plot for the purchase lead variable is displayed. Here, the alert instance in the drift plot is highlighted in red.
These results can also easily be obtained with the NannyML cloud platform. The cloud implementation offers numerous benefits over the open-source library implementation.
These benefits include:
- Ease of use UI display for data query and selection
- Reduction of engineering required for maintaining the code base
- Reduced energy devoted to monitoring infrastructure setup and orchestrating monitoring runs
- Straightforward data loading, avoiding confusion around data pulling and updating
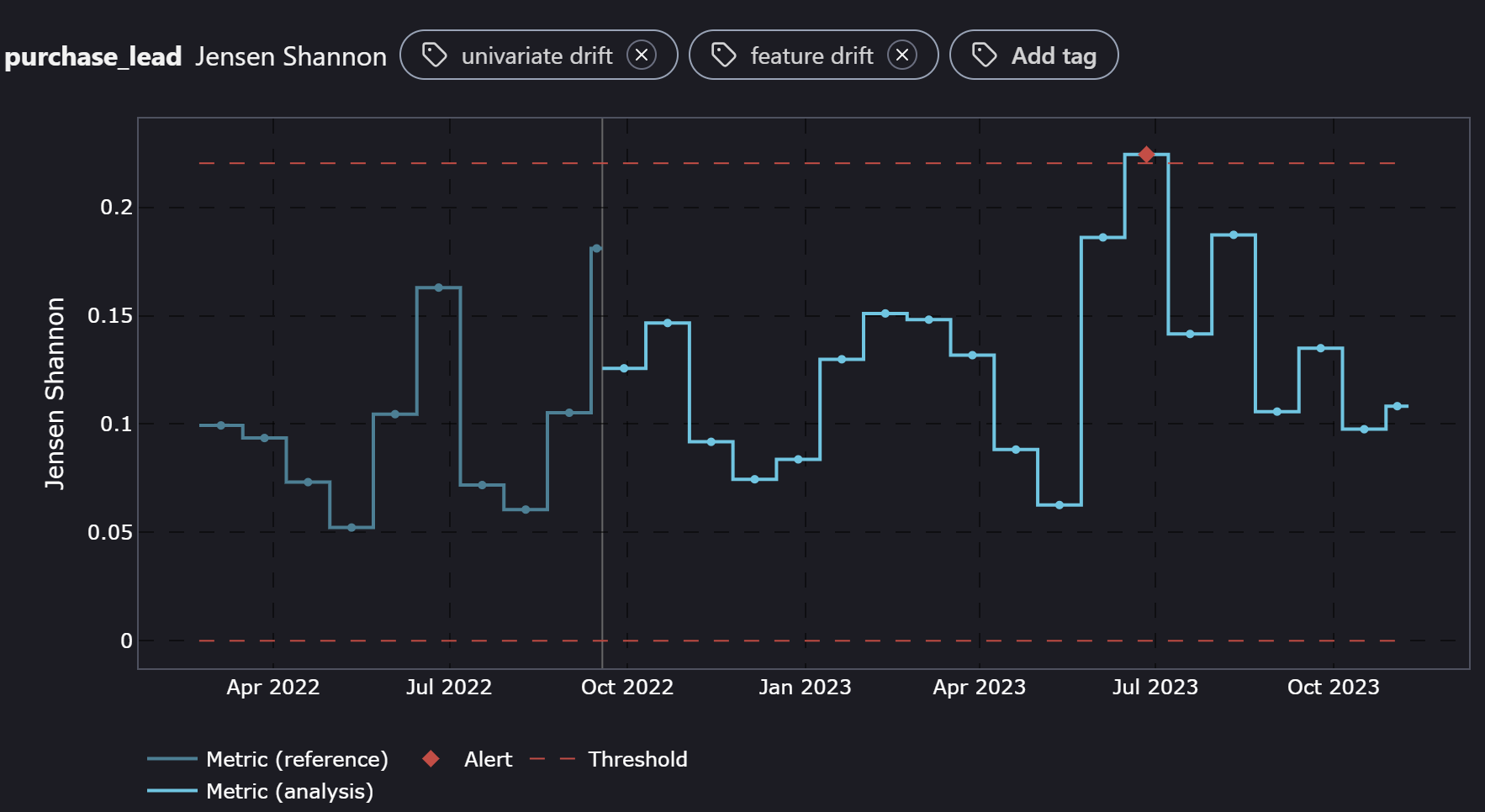
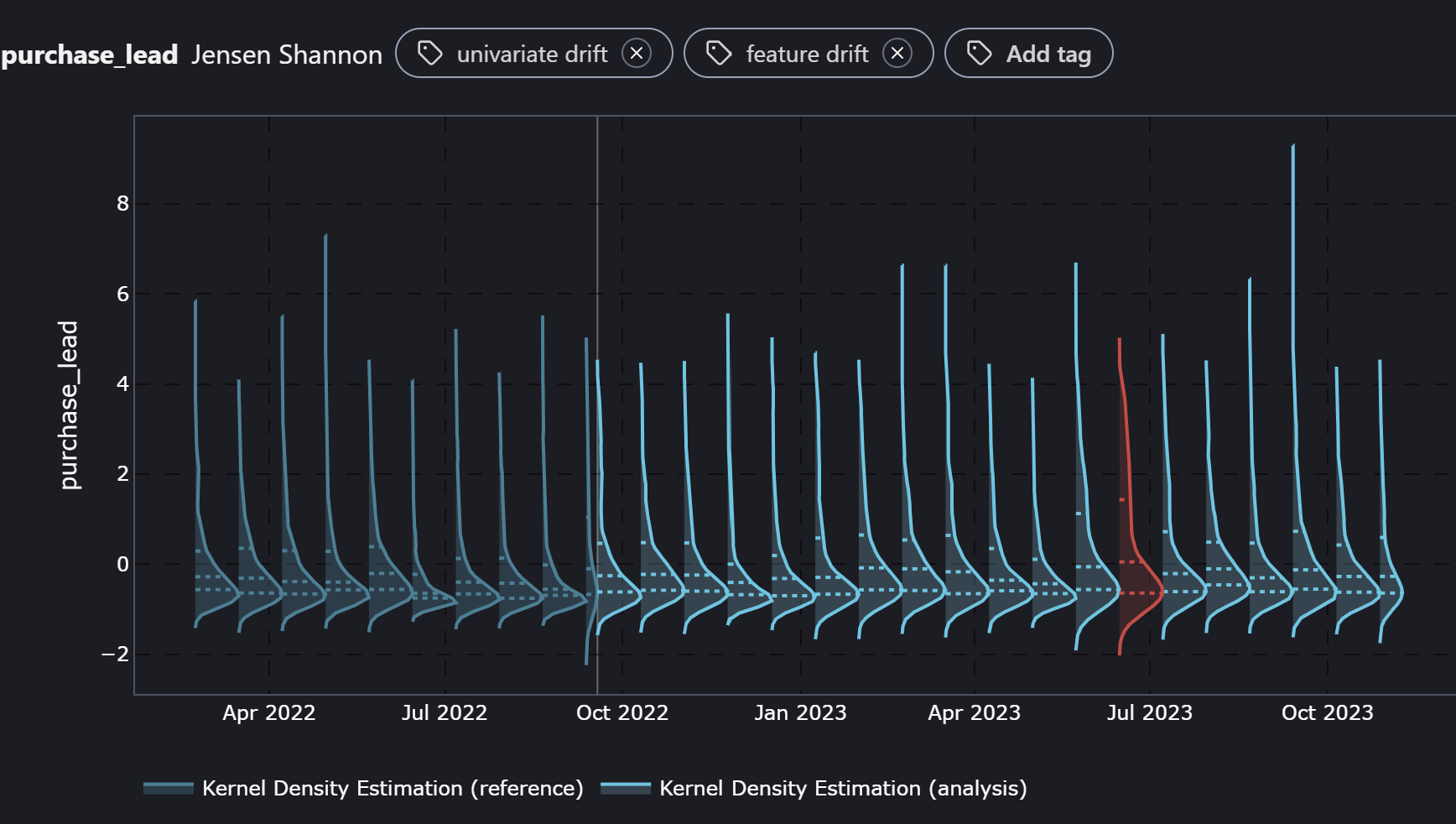
After preparing our CSV files of reference and monitoring data and loading them into the cloud service, there are several monitoring plots generated. Navigating to the Covariate Shift section, we can easily visualize both the univariate and multivariate data drift plots by selecting the relevant columns. These results are the same as our open-source plots in a fraction of the time and effort!
Multivariate Data Drift Method
For our multivariable methods, we will just be demonstrating our Data Reconstruction with PCA. See our tutorial on how to Detect Data Drift Using Domain Classifier in Python or the blog post, Multivariate Drift Detection: A Comparative Study on Real-world Data for more details on the Domain Classifier option.
As in our univariate method, we load up a calculator and set up the relevant parameters. More options for parameter setting can be found in the documentation for Data Reconstruction with PCA.
calc = nml.DataReconstructionDriftCalculator(
column_names=features,
timestamp_column_name='timestamps',
chunk_size=1080 # monitor every 7 days)
calc.fit(reference_df)
results = calc.calculate(monitor_df)Thereafter, the results are displayed and plotted via the code below:
display(results.filter(period='monitor').to_df())
display(results.filter(period='reference').to_df())
figure = results.plot()
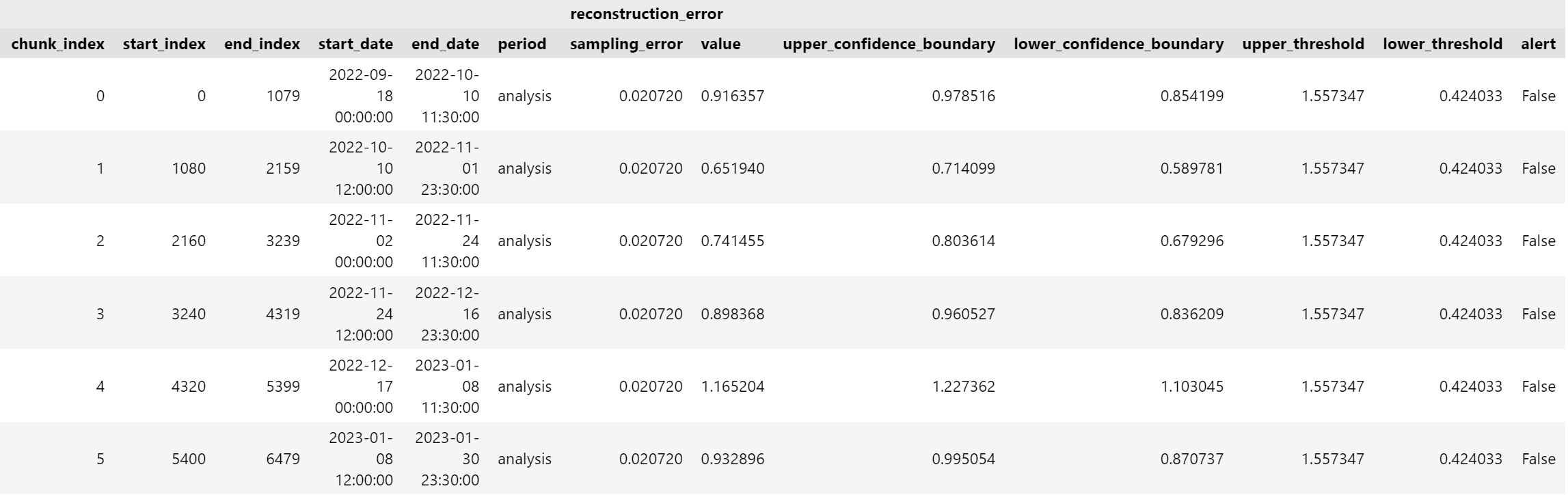
figure.show()For the basic display functionality, the precise values for the reconstruction error are provided for each chunk of data in addition to the most important metric on the far right: whether an alert has been triggered.
This information is far better represented in a graphical format for quicker analysis. The dotted red lines indicate the threshold region for alerts. The shadow blue line represents the confidence bound on the reconstruction error, and the solid blue line represents the actual reconstruction error metric.
In the multivariate drift for July 2023, however, no alerts are indicated despite the purchase lead alert noted in the Univariate Data Drift Method. This is because on average all other input features and their relationships remained within the specified threshold range.
Our cloud implementation plot matches our open-source implementation, while additionally providing dashboard-level interactivity and advanced functionality for data scientists to better understand their data drift!
Conclusion
To recap, using a Kaggle dataset, we showed how both NannyML’s univariate and multivariate data drift methods can be used to detect and investigate data drift. It is also important to note that data drift methods should only be used in the later stages of a machine learning monitoring pipeline as a tool for identifying the cause of model performance degradation. To understand why not to use data drift methodologies for performance degradation detection, check out this blog!
To give NannyML’s data drift methods a go on your data, we recommend checking out our open-source documentation or going straight to a free trial of our full host of post-deployment monitoring solutions via NannyML cloud to escape the infrastructural setup inconveniences.

Enjoyed this article - how about some more NannyML blogs?




Written by
