Table of Contents
- Introduction
- Need for Speed
- So, how did NannyML achieve these optimizations?
- Benchmarking Performance
- Speed-Up Results for Each Method
- Summary Statistics
- Univariate Data Drift Methods
- Multivariate Data Drift
- Let’s see that in action!
- Conclusion
- Looking for more insights on post-deployment? Explore these informative blogs!

Do not index
Canonical URL
Introduction
Do you frequently monitor your machine learning (ML) models using the NannyML open-source software (OSS) monitoring tools? Are you satisfied with the results yet hopeful for a few optimizations to help with better efficiency? We have some great news for you!
Our engineers have been working around the clock to make our OSS tools clock in faster. Our increasingly faster code base will assist in three major areas:
- Speedier alerts when the model’s performance degrades, leading to quicker rectification and restoring business value.
- Reduced code runtime leading to improved resource and compute allocations
- Potential to use developer time in a more optimized way
At NannyML, we constantly strive to bring our users the fastest tools for earlier model performance degradation alerts. This blog post will explore our current OSS speed-up optimizations through high-level implementation detail and benchmark comparisons. Additionally, the entire pipeline will be tested to demonstrate how you can get a potential 2.8x speedup using our newer methods.
Let’s dive into these improvements!
Need for Speed
Monitoring ML models, especially in real-time, can be challenging due to scalability and latency considerations, balancing resource constraints, handling diverse data sources, and above all actioning changes in the model once a performance hit has been noted.
To reduce these challenges, efficient monitoring tools are needed to scale with data volume and model complexity. Additionally, to ensure model performance can be investigated and corrected swiftly, timely insights on alerts are needed. Monitoring algorithms are subsequently required to be fast while operating within the computational constraints of the deployed environments.
So, how did NannyML achieve these optimizations?
- Removal of unnecessary pandas dataframe copying
- Replaced pandas dataframes with numpy calculations where appropriate
- Updated algorithm implementations to compute the same results in fewer steps
- Removed unnecessary computes like updating indices
.png)
Benchmarking Performance
The reported speedup results that follow have all been calculated on a standard NannyML benchmarking technique which uses the following procedure:
💡 Synthetic datasets were generated with either
make_classification or make_regression 💡 Datasets used 1000 features and 7M rows
💡 Models used were either
LGBMClassifier or LGBMRegressor 💡 The chunk size used is 320 000
💡 Each optimized method within the NannyML library was then run and compared to its older equivalent via the Profiler functionality from the
pyinstrument library.💡Speedup % was calculated via:
Benchmarking Disclaimer
It is important to note that all speed-up improvements represent ballpark figures from our benchmarking procedure and will likely differ based on the individual nature of each dataset in addition to the computing environment.
Speed-Up Results for Each Method
Now that we have established how the speedups were calculated, we can look at the specific improvements for each method.
Summary Statistics
Summary statistics enable us to monitor the basic statistical parameters of a data set such as the mean and standard deviation. These metrics are useful for intuitive data quality assessments and first-pass drift detection. Additionally, when summary statistics are taken from the reference data (data to establish a baseline of ML model expectations) - they can be used for setting up meaningful alert thresholds.
The NannyML OSS library enables 5 different summary statistics to be applied to feature columns. The speedups achieved in 4 of these summary statistics are detailed below based on the benchmarks run.
The speedups for the
.fit() method mean that the summary statistic code now runs significantly faster! In the worst case, it runs in 1/500th of the time of the older function (median summary statistic speedup). In the best case, it runs in less than 1/250th of the time (average summary statistic speedup). This is a substantial time saving, especially for large datasets..png)
.fit() function. Image by author.Univariate Data Drift Methods
Univariate data drift methods are useful for investigating silent model failure where an ML model’s performance degrades over time without showing any apparent failure signs, This leads to a sudden loss in performance which could impact profits, damage reputation, and impact customer relations. These methods assist in demonstrating the data distribution changes that may occur post-deployment. See A Comprehensive Guide to Univariate Drift Detection Methods for a fuller understanding of these methods.
In general, the speedups reported for these methods ranged from 6 to 13% for the
.fit() function and from 11 to 31% for the .calculate() function. This means that if you were to run a Kolmogorov-Smirnov & Chi-squared drift detection using both the new methods - the code would run in just over 4/5ths of the old code’s time.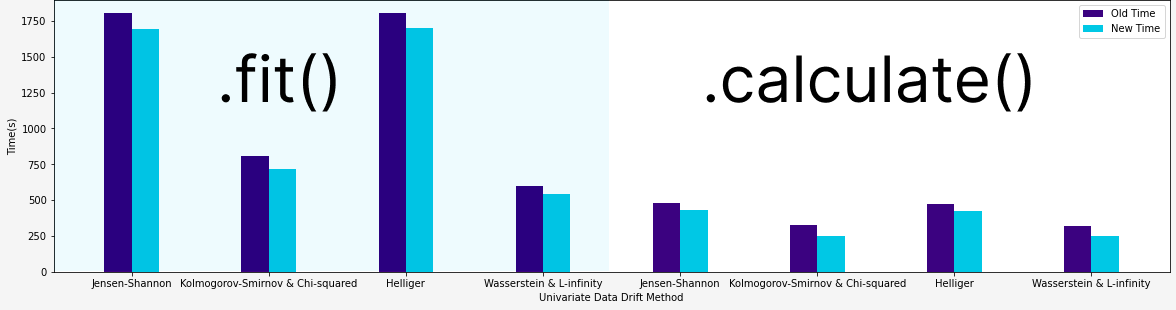
.fit() and .calculate() functions. Image by author.Multivariate Data Drift
Multivariate data drift detection is an important root cause analytical tool that helps to identify changes in selected features’ joint data distribution changes. This is especially relevant in reducing the risk of time wastage that can stem from starting to investigate univariate data drift methods that may not be impacting the performance.
NannyML offers two multivariate data drift detection algorithms: a Domain Classifier and a Data Reconstruction with PCA algorithm. Both multivariate algorithms allow data scientists to investigate how drifts across different features impact performance. A fuller comparison of when to use each algorithm is provided in Don’t Drift Away with Your Data: Monitoring Data Drift from Setup to Cloud.
One of the biggest speedups reported, however, was from the Data Reconstruction with PCA which has a speedup of 280% and 123% for its
.fit() and .calculate() functions respectively. This translates to a code that runs 3x faster than its older version!_(1).png)
.fit() and .calculate() functions. Image by author.Let’s see that in action!
To understand the overall speedup achieved, we compared the old functions to the new ones in a complete monitoring pipeline. We used NannyML’s synthetic car loan dataset, which predicts whether a customer will default on their car loan repayments.
For the comparison, each of the above methods is tested for both the old and new implementations and timed using the
process_time_ns() function.The old function versions of the NannyML OSS library take 4.109 seconds to finish running, while the new functions take only 1.484 seconds. This 2.8x speedup means your machine learning models can be monitored and updated in less than half the time! For data scientists and ML engineers, this translates to more efficient workflows, faster iterations, and quicker insights into model performance. Ultimately, this enhanced speed ensures your projects stay on track and responsive to real-time data shifts.
The full code used for timing is available here
The code was run in two different environments: one using the old NannyML functions and the other using the new sped up version.
# Library import
import nannyml as nml
from IPython.display import display
from time import process_time_ns
import pandas as pd
#Load data
reference_df = nml.load_synthetic_car_loan_dataset()[0]
analysis_df = nml.load_synthetic_car_loan_dataset()[1]
# Set all feature columns for NannyML methods
feature_column_names_first = [
'car_value', 'debt_to_income_ratio', 'driver_tenure'
]
column_names = ['car_value', 'salary_range', 'debt_to_income_ratio', 'loan_length', 'repaid_loan_on_prev_car', 'size_of_downpayment', 'driver_tenure', 'y_pred_proba', 'y_pred']
non_feature_columns = ['timestamp', 'y_pred_proba', 'y_pred', 'repaid']
feature_column_names = [
col for col in reference_df.columns
if col not in non_feature_columns
]
# Start the timer
t = process_time_ns()
# Average Calculator
calc = nml.SummaryStatsAvgCalculator(
column_names=feature_column_names_first)
calc.fit(reference_df)
results = calc.calculate(analysis_df)
# CBPE run with AUCROC and F1
estimator = nml.CBPE(
y_pred_proba='y_pred_proba',
y_pred='y_pred',
y_true='repaid',
timestamp_column_name='timestamp',
metrics=['roc_auc', 'f1'],
chunk_size=5000,
problem_type='classification_binary')
estimator.fit(reference_df)
results = estimator.estimate(analysis_df)
# Univariate Drift Calculator
calc = nml.UnivariateDriftCalculator(
column_names=column_names,
treat_as_categorical=['y_pred'],
timestamp_column_name='timestamp',
continuous_methods=['kolmogorov_smirnov', 'jensen_shannon'],
categorical_methods=['chi2', 'jensen_shannon'])
calc.fit(reference_df)
results = calc.calculate(analysis_df)
# Multivatiate drift calculator
calc = nml.DataReconstructionDriftCalculator(
column_names=feature_column_names,
timestamp_column_name='timestamp',
chunk_size=5000
)
calc.fit(reference_df)
results = calc.calculate(analysis_df)
# Get the final time
elapsed_time = process_time_ns() - t
print('Total time is:' ,elapsed_time/1000000000.0000,'s')Disclaimer
Speed up results may vary depending on the dataset size and compute resources available.
Conclusion
The enhancements to NannyML’s OSS Library significantly boost efficiency and performance, ensuring faster alerts, reduced code runtime, and increased developer productivity. By focusing on speed optimizations across various components, from summary statistics to multivariate data drift methods and CBPE, NannyML is committed to providing our users with efficient tools for maintaining optimal ML model performance.
The benchmark results demonstrate substantial improvements, with certain processes experiencing speedups resulting in code being speedup by 2.8x of the previous version underscoring the massive speedup gains achieved! Whether you're a long-time user or new to NannyML, these updates promise a more streamlined and responsive experience, helping you to address performance issues swiftly and effectively.
Are you ready to experience these improvements firsthand? Dive into our updated OSS tools today and witness the difference! Visit our documentation and unlock the power of accelerated monitoring with confidence.
Looking for more insights on post-deployment? Explore these informative blogs!



.jpg?table=block&id=73c9cea6-2fda-451f-94c6-1661be2aa5db&cache=v2)
Written by
